Background
Key features : NLP(Natural Language Processing), Language modeling objective, Transformer, Transfer learning, Masked Language Modeling(MLM), Next Sentence Prediction(NSP), Fine-tuning
BERT는 유명한 논문입니다. LSTM 구조의 모델에서 허덕이던 NLP계에 혜성같이 등장하여 11개의 NLP 벤치마크에서 SOTA를 달성하였습니다. BERT의 영향력은 엄청나 현재까지 BERT의 구조를 이용한 수많은 변형 모델들이 만들어졌습니다. 지금 생각나는 것만 나열해 봐도, RoBERTa, ALBERT, BART, MBERT, ViLBERT, SpanBERT, SciBERT, BioBERT, DeBERTa 등등... 정말 많습니다;; 그러나 그들의 아버지, BERT에 대해 이해하려면 우선 그들의 조상인 Transformer에 대해 알아야 합니다. 등장할 당시 큰 센세이션을 일으킨 논문, Attention is all you need, Vaswani et al. 2017은 인공지능을 연구하는 수많은 이들의 머리에 각인이 된 논문입니다. 해당 논문은 기존 LSTM 모델에서 적용되었던 Attention 메커니즘의 주요 문제점이었던 시간 의존성 - Auto-regressive 하게 계산되는 각 hidden state에 대해 한번에 처리할 수 있는 Self-attention 기법을 제안하였습니다. Transformer의 구조는 인공지능 연구에서 Attention이 필요한 다른 분야에도 쓰이고 있을 만큼 파급력이 큽니다! 자세한 모델 구조는 https://jalammar.github.io/illustrated-transformer/를 보시는 것을 추천드립니다.

그러면 독자들이 Transformer에 대해 안다고 가정하고 BERT가 나오게 된 배경부터 설명하겠습니다. 모르시는 분들은 위의 링크를 통해 공부하거나 논문을 보세요! (둘 다 보는 것 추천)
오늘날 어떤 자연어 문제를 풀기 위한 모델은 전이 학습을 통해 진행됩니다. 컴퓨터 비전의 전유물인 줄로만 알았던 전이 학습이 NLP에도 적용되기 시작한 것입니다! 전이 학습은 Pre-training과 Fine-tuning 단계로 나누어지는데, 자연어 모델에서 이루어지는 전이 학습은 Pre-training 단계에서 거대한 corpus(자연어 데이터의 집합이라고 보시면 됩니다.)를 통해 어떠한 Unsupervised Objective로 학습을 하여 자연어에 대한 일반적인 지식을 얻고, Fine-tuning을 통해 어떠한 자연어 문제(Question Answering, Text Classification, Summarization, Machine Translation, 등등...)를 해결할 수 있게 훈련됩니다. 즉 (쉽게 말하면!) 어떤 자연어 문제를 해결하는 인공지능을 만들 때는 우선 모델에게 자연어에 대한 전반적인 지식을 주입하고(Pre-training), 이후에 어떤 자연어 문제를 해결할 수 있도록 학습하는 것(Fine-tuning)입니다. 이 전이 학습에도 여러 기법들이 있는데......... 앗.. 점점 내용이 산으로 가니 시대적 배경을 BERT가 등장한 2018년으로 돌아가 봅시다..

때는 2018년.... 작년(2017년)에 Google에서 Transformer가 혜성같이 등장하고.... OpenAI에서는 이를 활용하여 GPT를 만들었다.... 기존에 적용되던 전이 학습 기법은 Word embedding(Glove), Context embedding(ELMo), Language Model fine-tuning(ULMFiT), Decoder-only Transformer(GPT).... 가 주로 사용되던 시대였다....
와우.. 지금은 2018년.. 제가 젊어졌어요..! 그러면 좀 어렵겠지만 BERT가 나온 이유에 대해 알아봅시다..!
Introduction
언어 모델을Pre-training 하는 것은 NLP 문제의 성능을 향상하는데 있어 아주 효율적입니다. 전이 학습을 위해 사용되는 모델 구조는 대표적으로 LTR(Left-To-Right) Transformer로 학습시킨 GPT(Decoder-only Transformer라고도 하죠?), Context feature를 중점으로 학습한 ELMo, Bidirectional LSTM으로 언어 모델을 학습시킨 ULMFiT이 있습니다.
이렇게 학습된 Language representation을 사용하는 두 가지 기법이 있는데, 바로 모델이 학습한 feature를 그대로 사용하는 방법과 전체 모델에 대해 어떠한 문제에 맞게 Fine-tuning 하는 방법이 있습니다. Feature 기반 학습의 대표적인 것이 바로 ELMo입니다. ELMo는 기존에 있던 word embedding을 다른 측면으로 일반화한 것입니다. ELMo는 LSTM 언어 모델을 LTR(Left-To-Right), RTL(Right-To-Left) 방식 2개를 개별적으로 학습시켜 어떠한 단어에 대해 각 레이어에서 나온 hidden state를 합친 것입니다. 한 문장에 대해 각 단어에 관한 Contextual Representation을 반영한 것으로 기존의 word2vec embedding의 문제점이었던 단어의 문맥적 의미를 반영하지 못한다는 점을 해결하였습니다. ELMo는 등장할 당시 특정 NLP 벤치마크(Question Answering, Sentiment Analysis, Named Entity Recognition)에서 SOTA의 성능을 달성하였습니다.
다음으로 볼 것은 Fine-tuning으로 학습하는 GPT(Generative Pre-trained Transformer)입니다. GPT는 미리 학습된 모델 파라미터를 어떠한 다운스트림 태스크에 맞게 모두 학습시킵니다. 엄청난 양의 corpus를 이용하여 모델을 미리 학습시키고(Pre-training), 어떠한 다운스트림 태스크에 대해 학습한다면(Fine-tuning), 적은 양의 데이터를 사용하더라도 충분히 좋은 성능을 달성할 수 있다는 것을 보여주었습니다. 등장할 당시 GPT는 GLUE 벤치마크에서 SOTA 성능을 달성하였습니다. ELMo와 GPT는 모두 같은 목적 함수를 통해 학습되는데, 이 두 모델의 최종 목표는 "단방향 언어 모델"을 학습하여 일반화된 언어 표현을 습득하는 것입니다.
그러나 BERT는 단방향으로 학습되는 언어 모델이 자연어 문제를 해결하는데 있어 성능을 저해하는 주요 문제점이라고 보았습니다. (않이, Transformer의 Self-Attention은 전체 입력 시퀀스에 대해 양방향으로 Attention을 한꺼번에 수행할 수 있는데, 왜 안 쓰는 거지?라는 의문점이 들었나 봅니다.) GPT는 LTR 구조로(이제 LTR이 뭔지 알겠죠?) 모든 입력 토큰이 이전 시간에 생성된 토큰과의 관계만을 학습하게 됩니다. 이러한 LTR 구조를 따르는 모델은 Sentence단위로 해결해야 하는 문제에서 성능이 좋지 못하며, 특히 양쪽의 문맥 모두를 고려해야 하는 Question Answering 문제를 수행하기에 적절치 못하다고 합니다.
이 문제를 해결하기 위해 BERT가 등장하게 됩니다. 아까 말한 단방향 모델의 한계를 극복하기 위해 새로운 모델, Masked Language Model을 제안하였습니다. Masked Language Model은 문장을 학습할 때 무작위로 단어를 가립니다(정확히 말하면 토큰). Pre-training 단계에서 모델의 목적은 한 문장에서 주변 단어와의 관계를 보고 Mask 토큰으로 가려진 단어가 무엇인지 찾아야 합니다. ("벌써 6시가 넘었다니, 빨리 <Mask>하고 싶다."라는 문장이 입력으로 들어오면 모델은 <M>에 어울리는 단어를 찾아야 합니다. - 여기선 당연히 "퇴근" 이겠죠? ㅠㅠ)
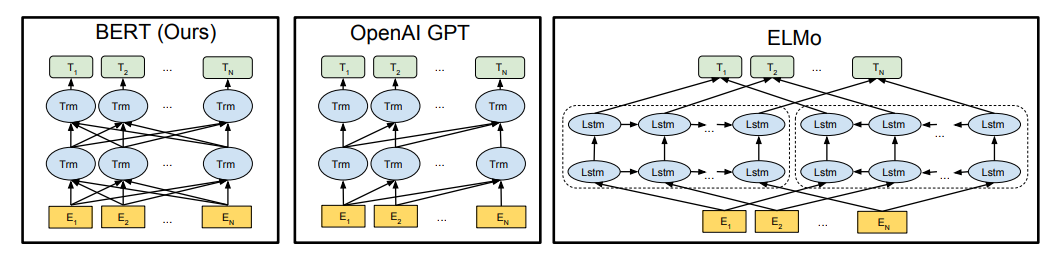
BERT에서 말하길, MLM(Masked Language Model)은 기존의 단방향 모델과는 다르게 가려진(Masked) 단어를 찾기 위해 모델은 가려진 단어 주변의 문맥 정보를 DEEP(깊)게 알고 있어야 한다고 합니다. 반대로 말하면 모델은 가려진 단어를 찾는 문제를 지속적으로 해결하여 전체적인 문장에 대한 문맥 정보를 파악할 수 있도록 학습된다는 것입니다. 또한 Next Sentence Prediction(NSP)를 추가적으로 도입하여 여러 문장과의 관계에 대해서도 학습할 수 있도록 하였다고 합니다. 해당 기법에 대한 자세한 설명은 밑에서 하도록 하겠습니다.
"어, 선생님! 그렇지만 앞서 설명한 ELMo는 양방향 정보가 반영된 것 아닌가요?"라고 물어보는 똑똑한 학생이 있을 겁니다.(한 명쯤은 있으리라 믿습니다...) 이에 대해 논문에서는 말을 덧붙였는데, ELMo도 양방향 정보를 반영하긴 하지만, 그냥 LTR 모델과 RTL 모델을 개별적으로 학습시켜 나온 값을 그냥 양 옆으로 덧붙였기 때문에 이는 DEEP(깊)은 문맥 정보를 반영하지 못하고 얕은 정보만을 반영하고 있다고 말합니다. 이렇게 DEEP이라는 단어를 강조하는 이유가 바로 ELMo Embedding과의 차이점을 강조하기 위함이었습니다! (Secret Revealed!)
이제 BERT의 약자가 무엇인지 확인해 볼까요?
BERT는 Bidirectional(양방향) Encoder Representation from Transformer의 약자였습니다!
위의 내용을 잘 이해하셨다면 그 뜻이 조금 짐작되실 것이리라 믿습니다.

구조
BERT는 Attention is all you need 논문에서 제안한 Encoder-Decoder 구조 중 Multi-Layer Bidirectional Transformer Encoder를 사용하게 됩니다. 이 Encoder 구조에 대해서는 기존 Transformer 논문을 읽어 봤다는 가정 하에 이루어 지기 때문에 생략하도록 하겠습니다. 그러나 Transformer의 Encoder 부분에 뭐가 있더라...? 하시는 분들께 간략하게 설명드리자면, 어떠한 문장이 입력으로 들어오면, 각 단어에 대한 Word embedding + Positional encoding을 수행한 뒤, 그 문장 안에 존재하는 서로 다른 단어들과의 관계를 Self-Attention으로 추출해 냅니다. 입력 문장 내의 다양한 특징을 반영하기 위해 여러 개의 Head로 나눈 뒤, 각 토큰과 입력 문장의 다양한 측면에서의 관계를 추출해 냅니다. 이를 Multi-head self-attention이라 합니다. 각기 다른 관계를 하나로 합친 뒤, 이후 Feed Forward Network를 거쳐 추가적인 특징을 학습하게 됩니다. 각 서브 레이어의 모든 출력 값에 정규화(Layer normalization)가 적용되고, 입력값과의 Skip-connection이 이루어집니다. 이게 하나의 Transformer layer이고, 실제 모델에서는 Layer를 여러 개 두어 Encoding이 진행됩니다. (어차피 모르는 사람은 간략한 설명을 봐도 모를걸요...? 그러니까 미리 공부하고 오세요.. ^^7)
BERT는 두 가지 단계로 학습됩니다. 바로 Pre-training과 Fine-tuning이죠. Pre-training에서는 모델이 레이블 되지 않은 데이터를 가지고 뒤에 나열할 두 가지의 태스크를 수행합니다. 그 뒤 Pre-training단계에서 미리 학습한 파라미터를 불러와 어떠한 레이블 된 태스크에 맞게 업데이트(Fine-tuning) 됩니다. 따라서 같은 Pre-trained 모델을 사용하지만, 풀고자 하는 문제에 맞게 Fine-tuning 하게 되어 독립적인 모델이 만들어지게 된답니다. 논문에서는 2가지 버전의 BERT를 훈련시켰습니다. BERT base는 12개의 Transformer 레이어, 768 hidden size, 12개의 멀티 헤드로 이루어져 있고, BERT large는 24 Transformer 레이어, 1024 hidden size, 16개의 멀티 헤드로 이루어져 있습니다. BERT base는 GPT와의 비교를 위해 만들었다고 합니다.
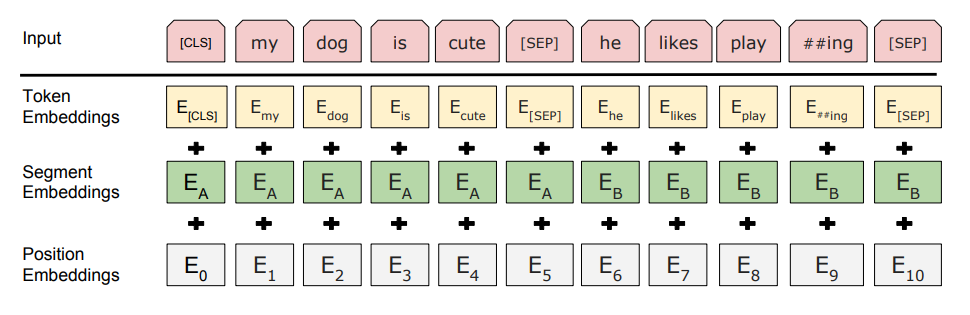
BERT를 여러 자연어 문제에 적용하기 위해서 입력으로 들어오는 시퀀스가 하나의 문장을 나타내는지, 두 개 이상의 문장을 나타 내는지 명확하게 알 수 있어야 합니다. 하나의 문장은 이전에 나온 문장과 이어진 문장일 수 있습니다. 따라서 이를 표시하기 위해 [SEP]라는 토큰을 추가하였습니다. SEP 토큰은 한 입력 시퀀스가 단일 문장인지 혹은 두 개의 문장이 합쳐져 있는지 알려주는 토큰입니다. 또한 한 시퀀스 안에 등장하는 단어가 어떠한 문장에 속해있는지 알려주기 위해 Segment embedding이라는 것을 추가하였습니다.
또 다른 BERT만의 요소로, 모든 입력 시퀀스의 첫 토큰은 [CLS](Classification Token)로 시작합니다. 이 CLS토큰의 역할은 Classification task를 풀기 위한 것으로 모든 엔코딩을 거쳐 나오는 final hidden state가 모든 입력 시퀀스의 정보를 반영하고 있을 것이라고 보았습니다.

BERT는 2가지 방법으로 문장을 구별합니다. 첫 번째는 [SEP]이라는 특수한 토큰을 이용하여 문장을 둘로 나눠 구분합니다. 두 번째는 모든 토큰에 학습된 임베딩을 추가하여 입력 시퀀스를 구성하고 있는 토큰 중 어떤 토큰이 문장 A, B에 속해있는지 표시하는 방법입니다. (일반적으로 Segment Embedding을 적용할 때 그냥 Sentence A에 속하는 토큰에다가 0, Sentence B에 속하는 토큰에다가 1을 더해줍니다.) 주어진 토큰에 대해 Positional, Segment, Token embedding의 값을 모두 합한 값이 그 단어의 최종 Input Embedding이 됩니다.
Pre-training
Pre-training 단계는 멀티 태스크 러닝이 적용됩니다. 하나는 짧게 설명드린 Masked Language Model(MLM), 다른 하나는 Next Sentence Prediction(NSP)입니다. 이 두 가지를 천천히 살펴보도록 합니다.
Masked Language Model
DEEP Bidirectional Model을 학습하기 위해 도입된 MLM은, 학습할 모든 입력 토큰 중 일부를 무작위로 바꾸고, 이를 모델이 학습하여 맞추게 하는 것입니다. 이렇게 학습하게 되면, [MASK] 토큰에 해당하는 final hidden vector가 모델의 Vocabulary로 Mapping 되는 최종 Softmax 레이어에 들어가 출력됩니다. 이는 기존 언어 모델을 학습하는 방법을 그대로 적용하면 됩니다. BERT는 전체 훈련될 토큰 중 15%를 무작위로 선택하여 가리고, 모든 입력에 대해 원래의 시퀀스를 생성하는 denoising autoencoder와는 다르게, BERT는 Mask로 치환된 단어 하나만 예측하게 된다고 합니다. 그러나 이러한 방식을 사용하여 Pre-train을 하면 fine-tuning에 대해 예기치 못한 문제가 발생할 수 있습니다. 왜냐하면 MASK 토큰이 fine-tuning 단계에서 등장하지 않기 때문입니다!! 그렇기 때문에, 전체 입력에서 가려질 선택된 15%의 토큰 중 80%는 기존 MASK 토큰으로 변환하고, 10%는 원래 단어가 아닌 무작위 토큰으로 바꾸고, 그리고 10%는 바꾸지 않는다고 합니다. 그런 다음, 각 단어에 대한 최종 hidden state vector를 사용하여 원래의 토큰을 추측하게 됩니다. 밑의 예시를 보면 좀 더 이해가 잘 가실 겁니다!

"이렇게 전체 데이터 셋에서 틀린 단어를 집어넣으면 언어 모델이 잘 학습이 안될 수 있지 않을까?"라고 의문을 가지는 똑똑한 학생이 또 있을 수 있습니다.(짝짝짝) 이에 대해 논문에서 설명하기론 전체 데이터에서 15%만큼의 토큰을 MASK토큰으로 선정하고, 그중 10%를 랜덤한 토큰으로 바꿉니다. 즉, 이는 전체 데이터셋의 1.5%밖에 해당되지 않아 모델이 전체적인 언어에 대한 이해를 하는데 큰 영향이 없을 것이라고 합니다. 또한 이러한 방식을 채택하게 되면 Transformer encoder가 최종적으로 어떠한 단어를 예측해야 될지 모르기 때문에 이를 맞추기 위해 모델은 강제적으로 모든 입력 시퀀스에 대해 문맥 정보를 유지해야 합니다.(어떤 단어를 문제로 낼 지 모르니 모든 문장에 대한 흐름을 파악하고 있어야 합니다..!)
Next Sentence Prediction (NSP)
다음으로는 Next Sentence Prediction에 대해 알아보겠습니다. 여러 자연어 문제 중 일반적인 언어 모델으로는 학습할 수 없는 문장 간의 관계를 이해해야 하는 Question Answering(QA)와 Natural Language Inference(NLI)가 있습니다. 이러한 문장의 관계성을 학습하기 위해 이진화 분류 문제인 Next Sentence Prediction 태스크를 추가적으로 도입하였습니다. 문장 A와 B를 pre-training 데이터에서 선택하고, 50%는 실제로 이어져있는 문장 (IsNext)로 구성하고, 나머지 50%는 전혀 관계없는 문장(NotNext)으로 구성합니다. 그저 두 문장이 이어져 있는가 이어져 있지 않은가를 맞추기만 하면 되는 아주 간단한 문제입니다. 그러나 이러한 간단함에도 불구하고, QA와 NLI 문제에 대해 아주 효과적이라고 합니다. NSP는 (Discourse-based objectives for fast unsupervised sentence representation learning) 논문에서 아이디어를 따왔다고 합니다. 그러나 이를 도입한 첫 논문에서는 해당 방식으로 Sentence embedding을 하여 문제에 적용되었지만(Feature-based), BERT는 모든 파라미터에 대해 전이 학습한다고 합니다. 이 역시 밑의 예시를 보면 이해가 더 잘 될 것 같습니다.
예시)
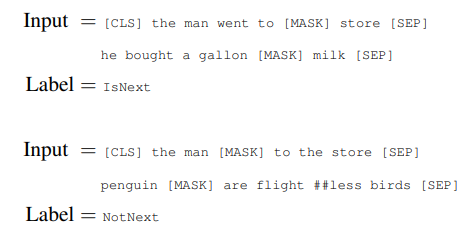
이렇게 도입한 MLM과 NSP로 Pre-training을 수행하여 모델은 언어에 대한 전반적인 지식을 얻을 수 있다고 합니다. 사실 추후 연구에서는 NSP 태스크가 문제 해결에 도움이 되는가에 대한 의문을 제기하였습니다. 이에 대해 자세히 알고 싶으시다면 RoBERTa 논문을 읽으시는 것을 추천드립니다. 결국 NSP 태스크는 두 문장 간의 관계를 학습하게 되는데, 이를 학습하기 위한 태스크로 NSP는 적절하지 못하다고 합니다.
데이터 셋은 Toronto Book Corpus와 English + Wikipedia를 사용하여 학습하였고, Wikipedia의 경우 list, table, header에 대한 정보를 뺐다고 합니다.
Fine-tuning
Fine-tuning단계에서 Transformer의 self-attention 덕분에 BERT 모델을 많은 자연어 문제에 적용하기 쉬워진다고 합니다! 보통 자연어 문제는 단일 문자열을 입력으로 하거나 두 문자열 쌍을 입력으로 사용하는 경우가 많습니다. 문자열 쌍을 입력으로 해야 하는 문제의 경우 보통 문자열 쌍의 관계를 알아내기 위해 Bidirectional Cross Attention을 적용해야 되는데, 이를 적용하기 위해 입력으로 들어온 문자열 쌍을 따로 Encoding 한 뒤 수행하게 됩니다. 그러나 BERT의 self-attention은 입력 문자열 쌍을 Encoding 하고 bidirectional attention을 적용하는 것을 한 번에 처리하는 효과를 낳습니다.(ㄴㅇㄱ!!) 이는 엄청난 장점으로 두 문자열 쌍을 입력으로 하는 문제와 한 문자열을 입력으로 하는 문제를 단일 모델, 같은 fine-tuining 방법으로 처리할 수 있게 되었습니다!
또한, 문장 제일 앞에 CLS 토큰을 도입하였었죠? 이 CLS 토큰을 이용하여 entailment 문제나 sentiment analysis 같은 Classification 문제를 풀 수 있습니다. CLS는 문장 내에 속하는 토큰이 아니고, 문장에 제일 앞에 위치해 모든 입력 시퀀스 전체를 바라볼 수 있는 효과를 가진다고 합니다.
그리하여 Fine-tuning 단계에서는 각각의 자연어 문제에 대해 문제에 맞는 입력과 출력을 BERT에 적용하고, 모든 Pre-train 된 파라미터에 end-to-end로 학습하면 됩니다! Fine-tuning은 Pre-training보다 비교적 시간이 오래 걸리지 않는다는 장점이 있습니다.
Experiments
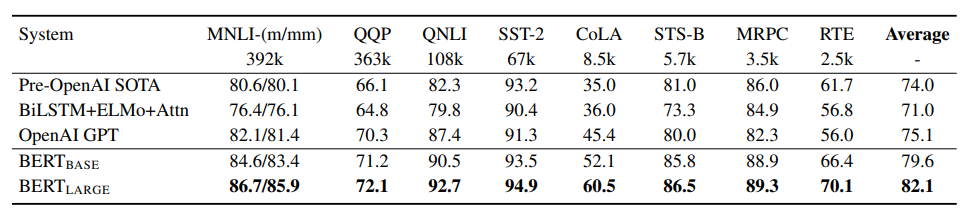
11개의 서로 다른 NLP 문제에 BERT를 적용하여 실험을 해봤다고 합니다. 결과적으로 모두 SOTA를 달성하였습니다. 여러 실험에 대한 세팅은 직접 논문을 읽어보시길 바라며 짧게 사용한 벤치마크와 결과를 올려드리겠습니다.
실험해 본 태스크
- GLUE(General Language Understanding Evaluation)
- GLUE는 사람이 쉽게 풀 수 있는 자연어 문제를 종류 별로 나눠 8개를 모아둔 벤치마크입니다.
- 대부분의 태스크는 Classification 문제이지만, 두 문장 간의 유사도를 수치로 나타내는 태스크(STS-B)인 Regression 문제가 하나 있습니다.
- SQuAD 1.1(Stanford Question Answering Dataset)
- Wikipedia에서 추출하여 만든 질의응답 벤치마크입니다. 지문과 질문이 주어지면, 모델은 지문 안에서 맞는 답을 찾아야 합니다.
- SQuAD 2.0
- SQuAD 1.1에서 짧은 답을 제거하고, 문제를 좀 더 현실적으로 가공한 데이터셋입니다.
- SWAG(Situations With Adversarial Generation)
- 어떤 문장이 주어지고, 그 뒤에 올 자연스러운 문장을 고르는 Multiple Choice 태스크입니다.
결과


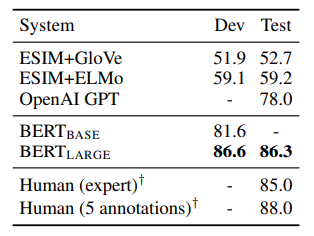
마치며...
이렇게 BERT를 알아보았습니다. BERT는 Transformer를 이용하여 다양한 NLP 문제를 처리할 수 있다는 것을 보여주었습니다. BERT는 Bidirectional Multi-Layer Transformer Encoder로 어떤 입력을 특정 도메인 내에서의 특징을 파악할 수 있도록 고정된 크기의 Vector로 Encoding 할 수 있다는 장점이 있습니다. 다양한 태스크에 대해서 BERT가 뽑은 Feature를 쉽게 사용할 수 있다는 것도 BERT가 사랑받는 하나의 이유가 아닐까 싶습니다. BERT의 등장과 함께 자연어 연구에 전이 학습에 대한 연구가 쏟아져 나왔고, BERT의 장점을 극대화하거나 단점을 개선한 수많은 개량된 버전이 나왔습니다. 현재(2021) 최고의 성능을 보여주고 있는 모델은 BERT의 구조를 따르는 모델이 아닌 GPT-3, T5-11B입니다. 그러나 아직까지도 BERT의 개량된 버전이 나오는 이유는... 바로 엄청난 컴퓨팅 자원이 필요로 하는 거대한 모델, GPT-3나 T5-11B를 Fine-tuning 하는 것은 엄청난 자본과 장비를 가진 거대 기업이 아닌 이상 힘들기 때문이겠죠. 더 많은 데이터셋, 더 거대한 모델은 성능 향상에 직결되지만 이는 우리가 사용하는 컴퓨터로는 돌리기 조차 힘들 정도로 많은 자원과 장비가 필요로 합니다. 나날이 발전하는 인공지능 모델을 우리 생활에서 쉽게 접하려면 모델을 좀 더 효율적으로 만들 수 있는 기술이 필요로 할 것입니다.
Reference
https://arxiv.org/abs/1810.04805
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional representations from unla
arxiv.org



