오늘 소개할 논문은 LibriMix라는 논문입니다. 이 논문은 2020년 Interspeech에 submitted 된 논문으로(억셉되지는 못했다고 하네요 ㅠㅠ) 자세한 내용은 아래 본문에서 설명 드리겠습니다.
최근 single-channel speech separation 을 위한 레퍼런스 데이터셋은 wsj0-2mix 데이터셋이 사용되는 것이 일반적입니다. 또한 대부분의 딥러닝 베이스 speech separation 모델들이 벤치마크로 본 데이터셋을 사용합니다. 그러나 최근 연구들을 보면 wsj0-2mix 에서 훈련된 모델들은 다른 유사한 데이터셋에서 평가될 때 상당한 성능저하가 일어났습니다. 이러한 이유로 generalization 문제가 발생했는데, 이 논문의 저자들은 이러한 문제를 wsj0-2mix 대신 사용할 수 있는 LibriMix라는 새로운 데이터셋을 만들어 해결하려고 합니다(심지어 이 데이터셋은 공짜예요! Wsj0 데이터셋이 150만원이 넘어가는 걸 생각하면 정말 좋죠).
LibriSpeech를 기반으로 하는 LibriMix는 ‘WHAM!’ 로부터 가져온 소음 샘플에 2명 또는 3명의 speaker(화자)를 혼합한 데이터들로 구성되어져 있습니다. 이 논문에서는 Conv-TasNet을 사용해서 앞으로 소개할 모든 LibriMix 버전에서 경쟁력 있는 성능을 달성했습니다. 또한 이 논문에서는 데이터셋 전체를 공정하게 평가하기 위해 LibriMix 데이터셋 말고 다른 데이터셋인 VCTK(영어 음성 데이터셋) 데이터셋을 베이스로 한 3번째 테스트를 소개합니다. 여기서 결국 LibriMix로 훈련된 모델의 generalization error 가 더 작다는 것을 보여주고 이를 통해 이 논문에서 소개하는 데이터셋이 일반화 성능을 향상시키는데 더 적절하다는 것을 확인시켜줍니다. 또한 보다 현실적이고 실제 대화와 유사한 시나리오에서의 평가를 목표로 LibriMix 테스트셋에 대해서 드문드문 overlapping 한 version도 출시했다고 소개합니다.
!!잠깐!! 여기서 WHAM! 이란 Wsj0 Hipster Ambient Mixtures의 약자예요. 즉 이 데이터셋은 wsj0-2mix 데이터셋에 whisper ai라는 곳에서 만든 고유한 백그라운드 노이즈와 합친 음성 데이터셋 이예요. 더 정확히 설명하면 노이즈는 2018년 말 샌프란시스코의 다양한 urban location 들에서 수집되었어요. 소음 환경은 레스토랑, 카페, 바 그리고 공원이라고 해요. 이 데이터셋은 아쉽게도 wsj0-2mix 라는 데이터셋을 필요로 하는데 wsj0 데이터셋은 유료이기 때문에 무료로 다운받을 수 있는 데이터셋은 노이즈 뿐이예요.
Intro
이제 제대로 논문에 대해서 알아봅시다. 먼저 실제 음향 환경에서의 robust한 speech processing에 대한 근본적인 문제는 입력으로 들어온 mixture recording에 존재하는 target source signal들을 추출하거나 separate할 수 있는다는데 있습니다. 현재까지 이러한 single-channel speech separation task의 SOTA는 딥러닝 기반입니다. 특히 time-domain 샘플을 직접 처리하는 end-to-end 모델이 최상의 성능을 얻습니다(time-domain 샘플을 직접 처리한다는 뜻은 음성 신호를 푸리에 변환과 같은 것을 하지 않고 raw data를 그대로 입력으로 사용한다는 의미예요). 이러한 모델들은 실제로 wsj0-2mix 데이터셋을 사용한 speech separation task에서 아주 잘 작동합니다. 실제로 모델을 통해 분리된 음성과 reference 음성에 대한 차이를 사람은 거의 느낄 수 없을 정도입니다. 이러한 점이 데이터셋 자체의 발전을 이끌었고, WHAM! 데이터셋과 같은 노이즈 데이터를 추가한 wsj0-2mix 의 확장버전으로 발전할 수 있었습니다.
이러한 데이터셋들은 보다 더 사실적인 모델 개발을 위해 만들어졌지만 아직 데이터셋이 완벽하지는 않습니다. 최근 실제로 wsj0-2mix 데이터셋을 사용해 Conv-TasNet을 훈련시키고 나서 다른 비슷한 데이터셋에 대해서 테스트를 수행했더니 상당한 성능 저하가 일어났습니다. 이러한 문제들은 wsj0-2mix 데이터셋에서 모델이 완벽한 성능을 달성한다고 하더라도 더 다양한 speaker들로부터의 음성 데이터셋이나 조금 다른 환경에서 녹음된 음성 데이터셋에 대한 generalize 능력은 아직 달성되지 못한 것을 확인할 수 있습니다. 추가적으로 모든 구간에 대해서 음성이 overlapping 되어있는 wsj0-2mix 와 같은 데이터셋은 사실 실제 환경과는 다르게 아주 이상하다는 것을 알 수 있습니다. 실제 환경에서는(회의, 저녁 파티 등의 상황) 일반적으로 overlap 비율이 약 20%이하 입니다. 실제로 몇몇 연구에 따르면 fully overlapping 데이터셋으로 speech separation 모델을 훈련시키면 sparsely 하게 overlapping된 데이터셋에 대해서는 잘 generalize되지 않는다고 합니다.
이 논문에서는 LibriMix를 소개합니다. LibriMix는 소음환경이 섞여 있는 generalization이 가능한 speech separation을 위한 데이터셋 입니다. Speaker는 두 명 또는 세 명이 섞여 있고, 버전에 따라 소음을 뺄 수도 있습니다. 이 데이터셋의 speech utterance들은 LibriSpeech 데이터셋에서 가져왔고 소음은 WHAM! 데이터셋에서 가져온 것입니다. 추가적으로 앞에서 간단히 말씀드렸던 VCTK 데이터셋에 기반한 추가 테스트셋은 공정한 cross-dataset 평가를 위해 설계했다고 합니다(일반화를 진짜 잘 하는지 확인하는 용도의 데이터셋 같아요). 이 논문에서는 LibriMix 데이터셋과 WHAM! 데이터셋을 통해 훈련시킨 Conv-TasNet의 generalization 능력을 평가하는데 뒤에 가서 결과를 보면 LibriMix 데이터셋이 소음이 있는 버전과 없는 버전 모두에 대해서 generalization을 더 잘하는 것을 확인할 수 있습니다. 이 논문에서는 여기에서 더 나아가서 실제 환경과 같은 테스트셋을 만드는데, 이 테스트셋은 다양한 크기로 overlap된 LibriMix 테스트셋의 sparsely overlapping 버전입니다. 이 데이터셋을 생성하는데 사용되는 스크립트 또한 공개 되어있어 손쉽게 만들 수 있습니다.
DataSets
그럼 이제부터 데이터셋을 살펴봅시다. 이 섹션에서는 WSJ0 데이터셋에서 파생된 기존 speech separation 데이터셋을 제시하고, LibriSpeech에서 파생된 이 논문에서 새롭게 만들어진 데이터셋을 소개합니다.
WSJ0, wsj0-2mix and WHAM!
WSJ0 데이터셋은 automatic speech recognition (ASR)을 위한 corpus로서 1992년에 만들어졌습니다. 이 데이터셋은 Wall Street Journal을 소리 내어 읽은 것으로 구성되어져 있고, 16KHz로 녹음 되어있습니다. 녹음은 close-talk로 했고 장비는 젠하이저 HMD414 마이크로 진행했습니다(이거 중고나라에서 팔더군요). Wsj0-2mix 데이터셋은 이렇게 만들어진 WSJ0 데이터셋으로부터 만들어진 데이터셋입니다.
Wsj0-2mix 데이터셋은 training set, validation set 그리고 test set으로 구성되어져 있습니다. Training과 validation set은 speaker들을 공유합니다(같은 화자들이 말한 corpus에 대해서 데이터가 구성되어져 있다는 거예요). 여기서 speech mixture들은 서로 다른 speaker들이 말한 utterance들의 pair를 임의의 signal-to-noise ratios (SNRs)로 만들어낸 것을 말합니다(SNR이란 말 그대로 신호대잡음비예요. 보통 높으면 높을수록 음질이 더 뚜렷해져요. 보통 설명할 때 원본 신호대비 잡음이 얼마나 섞여 있는지에 대한 비율로 표현한 일정한 형식의 값이라고 설명해요. 한마디로 신호에 잡음이 얼마나 섞여 있는지에 대한 비율인 거예요. 단위는 db이고 이게 높을수록 좋은 이유는 비율이기 때문이예요). 임의의 SNR은 0 ~ 5db 사이에서 균일하게 나타내어집니다. Wsj0-2mix는 4가지 데이터셋 변형을 사용할 수 있는데, 2가지 다른 sampling rate(16KHz, 8Khz)와 2가지 모드(min, max)가 이에 해당합니다. 먼저 min 모드는 짧은 utterance에 대한 크기만큼의 길이를 가지는 데이터셋이고, max 모드는 더 긴 길이의 utterance에 대한 크기만큼의 길이를 가지는 데이터셋 입니다. 이때 짧은 utterance는 합쳐질 때 남은 길이에 대해서 0으로 padding 됩니다. Wsj0-2mix 데이터셋과 마찬가지의 방법으로 세 명의 speaker들에 대한 mixture 데이터셋인 wsj0-3mix 데이터셋도 만들어집니다.
WHAM! 데이터셋에서는 wsj0-2mix 데이터셋이 노이즈를 함께 포함하도록 확장했습니다. 이 데이터셋에 대한 설명은 위에서(!!잠깐!! 섹션) 했습니다.
LibriSpeech, LibriMix and sparse LibriMix
LibriSpeech는 LibriVox 라는 public domain audiobooks를 기반으로 한 ASR corpus 입니다. Reference signal들에서 백그라운드 노이즈를 피하기 위해 이 논문에서는 LibriSpeech의 특정 subset들만(train-clean-100, train-clean-360, dev-clean 여기서 100과 360은 training dataset의 시간을 나타내요. 그리고 dev는 이 논문에서는 validation set으로 사용돼요. 마지막으로 test를 위한 test set이 있어요) 사용합니다. 이 데이터셋은 60k 어휘와 1,252명의 speaker들로부터 약 470시간의 speech를 나타냅니다.
이 논문에서는 LibriSpeech와 WHAM! 로부터 파생된 새로운 데이터셋인 LibriMix를 제안합니다. 이 데이터셋은 완전한 오픈소스 입니다(와 정말 짱 이예요)!
이 데이터셋에는 두 개의 메인 데이터셋이 있는데, Libri2Mix와 Libri3Mix 입니다. 이 데이터셋들은 노이즈가 있는것과 없는 것이 있고, 각각 두 명 그리고 세 명의 speaker들의 mixture로 구성되어져 있습니다. 또한 Libri2Mix의 구조는 WHAM! 데이터셋과 완전히 같고 동일한 tasks를 시행할 수 있습니다. 이 데이터셋에서는 wsj0-2mix에서와는 다르게 signal의 power를 사용하지 않고 LUFS(단위 db)라는 것을 사용해서 각 utterance들의 signal을 scale 합니다(LUFS는 유럽 방송 연맹의 EBU R128 표준에서 제시된 것인데, 전체 오디오 레벨의 크기라는 점에서 power와 비슷하다고 할 수 있지만 power가 오디오 신호의 전체 주파수 대역을 가감없이 측정한 것이라고 한다면 LUFS는 오디오 신호의 전기적인 세기 외에도 사람이 실제로 느끼는 소리의 크기를 가청 주파수 대역, 소리가 작거나 없는 구간 등을 모두 고려해서 계산한 것이라고 할 수 있어요. 사실 이건 유튜버들이 잘 알죠. 유튜브 올릴 때 이걸 고려해서 올린다고 하니까요). 기존의 SNRs와 LUFS를 비교하면 LUFS가 인간의 지각과 더 잘 연관되어서 좋습니다. 또한 다운샘플링에도 민감하지 않습니다.
Speech mixture는 서로 다른 speaker에 대한 utterance를 랜덤하게 선택해서 생성됩니다. 각 utterance의 loudness는 -25 ~ -33 LUFS에서 균일하게 샘플링 됩니다. 또한 랜덤 노이즈의 loudness는 -38 ~ -30 LUFS 사이에서 균일하게 샘플링 되고, 그 다음 speech mixture에 추가됩니다. 이 결과를 SNRs로 보면 다음과 같습니다. 우선 노이즈가 없는 데이터셋에 대해서 보면 평균은 0db이고 분산이 표준 편차가 4.1db을 갖는 정규분포로 되어있습니다. 다음으로 노이즈를 포함하는 데이터셋을 보면 평균은 -2db이고 표준 편차는 3.6db을 갖는 정규분포로 되어있는 것을 확인할 수 있습니다.
Train-100과 train-360에서 각 utterance는 한 번만 사용됩니다. Dev와 test의 경우 3000개의 mixtures를 도달할 때 까지 동일한 절차를 충분히 반복합니다. 이로 인해 WHAM! 데이터셋의 경우 45시간이었는데 이 작업을 통해 약 280시간의 노이즈가 있는 speech mixtures를 생성할 수 있습니다. 이제 이 논문에서 만든 데이터셋은 기존 WHAM! 데이터셋이 100명의 개별 speaker들을 가지고 있던 것에 비해 훨씬 많은 1,000명의 개별 speaker들로 구성되어졌습니다. 또한 유일한 단어 또한 wsj0-2mix에서보다(5k 개) 훨씬 많아졌습니다(60k 개).
보다 사실적이고 실제 대화와 유사한 시나리오를 위해 한걸음 더 나아가 LibriMix 데이터셋의 두 명 및 세 명의 speaker test sets의 sparsely overlapping 버전도 출시했으며, 이 데이터셋을 각각 SparseLibri2Mix 및 SparseLibri3Mix 라고 합니다(sparse 데이터셋은 only testset 이예요).
두 명 및 세 명의 speaker 버전들 모두에 대해서(여기서 말하는 것은 SparseLibriNMix 데이터셋 이예요) 6개의 서로 다른 양의 speech overlap(0%, 20%, 40%, 60%, 80% 그리고 100%)을 사용해서 500개의 mixture들을 생성했습니다. 이에 대한 예시는 아래 그림에서 확인 가능합니다.

VCTF and VCTK-2mix
이 논문에서는 또한 VCTK-2mix 테스트 데이터셋도 제공합니다. VCTK는 109명의 원어민 영국 speaker들을 포함합니다. 이들이 신문을 읽고 그 데이터가 VCTK 데이터셋 입니다. VCTK 데이터셋의 utterance들에는 상당한 양의 무음 데이터가 포함되어있어 이 논문에서는 energy-based VAD를 사용해서 무음 부분을 적절히 제거했습니다. VCTK-2mix를 위한 mixing은 앞에서 살펴본 LibriMix 데이터셋과 동일한 방법을 통해 만들어 집니다. 노이즈 샘플은 당연히 WHAM! 데이터셋의 데이트셋으로부터 가져옵니다. 결과적으로 이 데이터셋은 3,000개의 utterance를 108명의 speaker들로부터 읽어 들여 9시간의 크기를 갖는 테스트를 위한 데이터셋입니다.
Results
이제 결과를 알아봅시다. 일단 이 논문에서는 LibriMix 데이터셋을 사용해 얻을 수 있는 결과를 평가하기 위해 Conv-TasNet 을 사용합니다. 그리고 평가는 SI-SDR을 사용합니다. SI-SDR의 경우 무음 데이터에 대해서는 정의되지 않으므로 모든 max 버전에서 보고된 결과는 일치하는 min 버전에서 학습된 모델에 해당합니다.
Results on LibriMix
아래 표에서는 Conv-TasNet을 사용해 노이즈가 없는 데이터셋과 노이즈가 있는 데이터셋 버전에 대한 Libri2mix와 Libri3Mix의 결과를 볼 수 있습니다. 이 결과값들은 STFT에 대한 IBM과 IRM 값들에 대한 SI-SDR값과 비교됩니다. 여기서 비교한 Conv-TasNet은 train-360 데이터셋에 대해서 학습되었는데, 그 이유는 train-100 데이터셋보다 성능이 더 좋았기 때문입니다. 아래표를 보면 Input 칼럼이 있는데, 이것은 입력 mixture에 대한 SI-SDR값 입니다. 즉, 여기서는 입력에 대해 얼마나 SI-SDR값이 향상되었는지에 대해 결과를 비교합니다. 표를 보면 가장 왼쪽 칼럼에 2spk-C와 2spk-N이 있는데 이는 각각 clean 데이터셋과 noise 데이터셋을 나타냅니다. 보시면 아시겠지만 3mix는 노이즈가 없든 있든 성능이 떨어지는 것을 확인할 수 있습니다.

Results on SparseLibriMix

이 논문에서는 위에 표에서 볼 수 있듯이 SparseLibri2Mix와 SparseLibri3Mix의 8KHz 테스트셋에 대한 결과를 보고합니다. 여기도 역시 노이즈가 없는 데이터셋과 노이즈가 있는 데이터셋이 있습니다. 이 데이터셋을 평가하기 위해 위에서 사용한 8KHz non-sparse 데이터셋에 대해 학습한 모델을 사용합니다. 이 테이블의 결과에 대해서 두 명 그리고 세 명의 mixture 모델을 보면, overlap이 높으면 SI-SDR이 낮은 것을 확인할 수 있습니다. 100% overlap된 경우 당연하지만 Table 4 와 유사한 결과를 얻을 수 있습니다. 왜냐하면 Table 4 는 100% overlap된 데이터셋이기 때문입니다. 흥미롭게 볼 점은 overlap이 작을 때 Conv-TasNet의 성능은 IRM과 비교했을 때 작습니다. 이는 sparsely overlapping mixtures 데이터셋에 대한 speech separation 모델의 개선 여지가 있음을 의미합니다.
Dataset comparisons
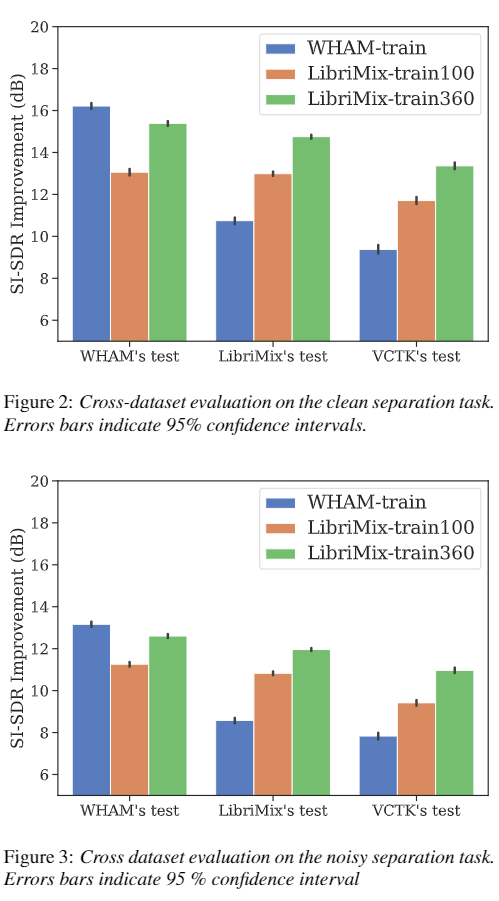
최근 연구에서는 speech separation 모델이 wsj0-2mix 데이터셋에 대해서 학습됐을 때 다른 데이터셋에 대해서는 적절히 generalize를 하지 못한다는 것을 확인했습니다. 이런 연구와 비슷하게 이 논문에서도 다른 데이터셋으로 Conv-TasNet을 학습했을 때 모델의 generalization 능력을 확인하는 연구를 진행했습니다. 이 논문에서는 여섯 개의 다른 Conv-TasNet 모델들을 WHAM! train, LibriMix train-100, train-360 데이터셋의 노이즈가 없는 버전과 있는 버전 둘 다에 대해서 학습을 진행합니다. 이 모델의 결과에 대한 것은 위 그림에서 볼 수 있습니다. 위 그림에서 Fig. 2 는 노이즈가 없는 것에 대한 결과이고 Fig. 3 은 노이즈가 있는 데이터에 대한 결과입니다. 일단 여기서 알고 계셔야 할 것은 모든 테스트셋에 대한 노이즈 샘플이 일치한다는 점입니다(노이즈에 대한 데이터셋은 WHAM! 에서 가져오기 때문에 어쩔 수 없어요). 그럼 결과를 봐 봅시다. 노이즈가 없는 데이터와 노이즈가 있는 데이터 둘 다에 대해서 WHAM! 으로 학습된 모델은 separation task에서 좋지못한 generalize 성능을 보여줍니다. LibriMix 데이터셋에 대해서 LibriMix로 학습된 모델과 비교했을 때, 약 4db 정도 떨어진 성능을 보여주는 것을 위 그림에서 확인할 수 있습니다. 반면에 LibriMix로 학습된 모델은 WHAM! 테스트셋에서 비교했을 때 아주 약간의 차이밖에 발생하지 않았습니다. VCTK-2mix 테스트셋에 대해서도 WHAM! 데이터셋으로 학습된 모델은 성능이 좋지 않지만 LibriMix 데이터셋으로 학습된 모델은 성능이 다른 테스트셋과 비교했을 때 비슷한 것을 확인할 수 있습니다. 이 결과에서 보면 LibriMix의 train-100과 train-360 데이터셋에 대한 모델의 성능차이가 심한 것을 확인할 수 있는데, 이를 통해 generalize의 핵심 키는 데이터의 양이라는 것을 확인할 수 있습니다. 결과를 보면 WHAM! 데이터셋의 양이 매우 불충분한 것을 확인할 수 있습니다. 이 결과를 통해 노이즈가 없는 버전과 있는 버전 모두에 대해서 LibriMix 데이터셋이 wsj0-mix 데이터셋보다 더 좋은 generalization 성능을 보여주는 것을 확인할 수 있습니다.
이 논문에서는 generalization을 위한 몇몇의 요인이 있을 수 있다고 합니다. Speaker들의 수, 어휘의 개수, 녹음 환경 그리고 트레이닝 데이터의 양이 그 요인일 수 있다고 하고 이러한 것들 덕분에 LibriMix train-360 데이터셋이 generalization을 잘 한다고 설명합니다.
Conclusions
이 논문에서는 LibriMix라는 새로운 데이터셋을 만들고 오픈소스로 제공합니다. 이 데이터셋은 generalization이 가능한 single channel speech separation을 위한 오픈소스 데이터셋입니다. 또한 이 데이터셋은 노이즈를 포함한 버전과 포함하지 않은 버전이 있습니다. 더욱 실제 환경과 같은 데이터셋을 만들기 위해 sparse하게 overlap되어있는 데이터셋인 SparseLibriNMix 또한 제공합니다. 이 데이터셋을 통해 학습하고 테스트한 결과를 보면 이러한 실제 환경과 같은 상황에 대해서는 개선의 여지가 있음을 시사합니다. 다음에는 sparse overlap speech mixture 데이터셋에 다양한 노이즈 샘플이 포함된 데이터셋을 디자인해서 제공한다고 합니다. 이렇게 오픈소스 데이터셋인 LibriMix 데이터셋에 대해서 알아봤습니다. 개인적으로는 wsj0-mix 데이터셋보다는 이런 다양한 데이터셋이 많아져 벤치마크가 풍부 해졌으면 좋겠다는 바램이 있습니다.
Reference
https://arxiv.org/abs/2005.11262
LibriMix: An Open-Source Dataset for Generalizable Speech Separation
In recent years, wsj0-2mix has become the reference dataset for single-channel speech separation. Most deep learning-based speech separation models today are benchmarked on it. However, recent studies have shown important performance drops when models trai
arxiv.org



