Background
Key features : NLP(Natural Language Processing), BERT, Fine-tuning, ADAM Optimizer, Catastrophic Forgetting, Machine learning Engineering, Fine-tuning instability, Bias Correction
자연어 처리를 연구하다보면 BERT 모델과 접할 기회가 많습니다. 많은 논문들이 더 크고 더 많은 데이터로 학습시킨 모델이 더 좋은 성능을 낼 수 있다고 말하고 있고, 이는 자연어 처리 뿐만아니라 이미지 처리, 아니 모든 인공지능 모델에 적용되는 공통 사항입니다. (요새는 일반 사람들의 컴퓨터에 만들어진 모델을 GPU에 로드하지도 못할만큼 큰 모델이 등장하고 있습니다. 슬프게도 말이죠..) 따라서 자연어 처리를 연구하다보면.. 나도 저 거대한 모델을 학습시키고 싶다라는 생각을 가지게 됩니다 (저만..그런거 아니죠?), 그러나 직접 BERT large 모델을 Huggingface를 통해 받아오고 Fine-tuning을 시작하다 보면.. 어라..? 왜 학습이 안되지..? 하는 경험이 있으실거에요 (없으셔도.. 괜찮습니다! 지금부터 알면되니까요) 어쩔땐 되고,, 어떨땐 안되고,, 분명히 같은 모델이고 같은 코드인데.. 데이터셋이 잘못됐나..? 도대체 뭐가 잘못된거지..? 한참을 찾아다녔던적 있습니다. 오늘의 논문은 바로 이 문제, 큰 모델을 미세조정(Fine-tuning)하는데 있는 어려움을 해결하기 위한 논문입니다! 잘 모르시는 분들도 아, 트랜스포머 기반 모델의 전이학습에는 이런 문제점이있구나 하고 알아가시면 좋으실거 같고 BERT나 다른 파생 모델을 학습시키는데 Base크기의 모델에서는 학습이 잘되는데 Large 모델을 학습시키는데 어려움을 겪으신 분들은 꼭 읽어보시면 좋을것 같습니다. BERT와 자연어 처리에서 사용되는 전이학습과 BERT 모델에 대한 개념을 잘 모르신다면 이 블로그에서 제가 작성한 BERT에 대한 논문 리뷰를 먼저 읽고 오시는 것을 추천드립니다! BERT 리뷰 보기

오늘 리뷰할 논문은 ICLR 2021에 Accept된 비교적 최신 논문입니다. 제안된 논문의 흐름을 그대로 따라가며 설명하기 때문에 내용이 조금 길 수 있습니다! 그러나 자세히 알고싶으신분들은 꼭 본문을 다 읽어주세요! 시간이 없으신 분들은 가장 밑의 요약만 보셔도 됩니다. 모르는 부분은 덧글로 남겨주시면 감사하겠습니다.
자 우선 전체적인 논문의 내용을 요약해서 살펴 봅시다.
- Pre-trained된 BERT모델을 Fine-tuning하는 것은 다양한 NLP 벤치마크에서 리더보드의 상위권을 장악하고 있다.
- BERT를 Fine-tuning하는 것은 매우 "불안정"하다고 알려져있다.
- 이전 연구에서는 이를 2가지 문제일 것이라고 보았다 - Catastrophic forgetting과 Small training dataset
- 이러한 Fine-tuning 불안정성을 설명하기 위해 BERT, RoBERTa, ALBERT를 GLUE 벤치마크로 여러번 Fine-tuning하여 실험을 하였다.
- 결론적으로 이는 Optimization difficulties(최적화의 어려움)이 주요 문제이며, 이는 Vanishing gradient(기울기 소실)문제를 야기한다.
- 다운스트림 태스크의 성능이 일정하지 않은 또 다른 이유는 같은 loss로 훈련된 미세 조정(Fine-tuning) 모델이 서로 다르게 일반화되어 테스트 성능이 확연하게 달라진다는 것이다.
요약만 봐서는 잘 모르겠죠? 그러면 본문으로 들어가봅시다!

Pre-trained Transformer-based Masked Language Model (BERT, RoBERTa, ALBERT, BART, 등등..)은 오늘날 NLP 연구에 엄청난 파장을 불러일으켰습니다. 이러한 모델은 일반적으로 사전학습된 모델을 어떠한 다운스트림 태스크에 몇 에폭동안 학습시키는 것으로 문제를 해결합니다. 이는 다른 말로, Fine-tuning(미세 조정)이라고도 합니다. Fine-tuning 방법론은 GLUE나 SuperGLUE와 같은 여러 NLP 벤치마크를 장악하게 되면서 실험적으로 주목할 만한 결과를 보여주었지만, 우리는 아직도 Fine-tuning에 대해 잘 알지 못합니다. 왜냐하면 Fine-tuning을 수행하면 모델이 학습 데이터의 부정확한 패턴이나 편향을 학습할 뿐만 아니라, 불안정한 학습을 보여주기도 하기 때문입니다. 그렇다면 불안정한(unstable) 학습은 무엇일까요? 불안정한 학습은 같은 데이터셋으로 같은 모델을 랜덤 시드만 바꾸어 여러번 Fine-tuning 했을 때, 보여주는 모델의 성능(예- 정확도)의 편차가 매우 크다는 뜻입니다.
이러한 불안정성을 해결하기 위한 몇개의 방법론이 제안되지만, 왜 Fine-tuning이 이러한 실패를 겪기 쉬운지에 대한 충분한 설명은 이루어지지 않았다고 합니다. 따라서 이 논문의 목적은 Fine-tuning의 불안정성을 설명하기 위함입니다. 논문을 관통하는 주제는 다음 질문을 해결하는 것으로 나타낼 수 있다고 합니다.
BERT-large 모델의 Fine-tuning은 왜 실패하기 쉬우며 불안정성을 개선하기 위해 어떻게 해야 하는가?
우선 해당 논문은 Fine-tuning 불안정성에 대한 흔히 알려져 있던 두가지 가설에 대해 조사하는 것으로 시작합니다. 1) Catastrophic forgetting과 2) Small Size of the Fine-tuning Dataset(작은 훈련 데이터셋)입니다. 이 두 가설은 Fine-tuning 불안정성을 설명하는 대표적인 가설인데요, 이 논문에서는 결과적으로 이 가설들이 틀렸다는 것을 설명하고 있습니다. 해당 가설이 틀렸다는 것을 보여주고 난 다음으로는 GLUE 벤치마크를 이용해 Fine-tuning이 왜 실패하는지에 대해 조사하고, 저자는 이러한 불안정성이 두가지 개별적인 측면으로 나누어질수 있다는 것을 발견하였다고 합니다. 저자가 찾은 원인으로는 다음 두가지가 있습니다. 첫번째론 1) 학습 초기의 최적화의 어려움(Optimization Difficulties) 때문입니다. 이는 Vanishing gradient(기울시 소실)이 일어난다는 것을 통해 확인할 수 있습니다. 두번째로는 2) 학습 후기의 모델의 서로 다른 일반화(Gerneralization) 때문입니다. 이는 거의 같은 훈련 로스를 갖고 있지만 Validation 혹은 Development 데이터셋에서 서로 다른 성능을 보이는 것으로 확인할 수 있습니다. (Validation 데이터셋과 Development 데이터셋은 같은 개념입니다. 모델을 훈련시키는데 사용하는 데이터셋으로는 Training-Development/Validation-Test 이렇게 3가지 종류가 있습니다. 유명한 벤치마크 데이터셋의 경우 Test 데이터셋을 공개하지 않는 경우가 많습니다.)
저자는 해당 분석을 통해 간단하지만 강력한 Fine-tuning 모델을 위한 훈련 베이스라인을 만들었습니다. 그리고 제안한 베이스라인이 BERT에만 사용할 수 있는 것이 아니라 비교적 최근에 나온 사전 학습 모델인 RoBERTa와 ALBERT에도 적용될 수 있다고도 합니다. 자 그럼 실험에 사용한 데이터셋과 하이퍼파라미터 세팅을 알아봅시다.
- 데이터셋
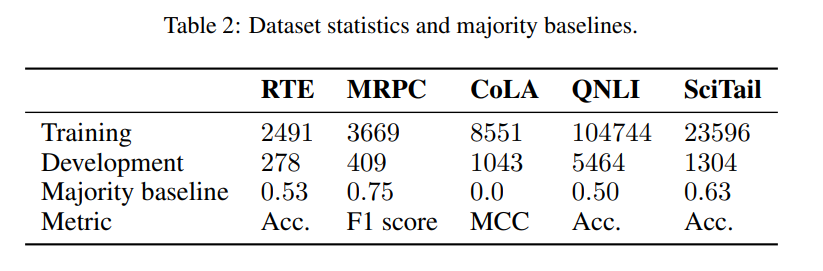
이전 연구에서 Fine-tuning 불안정성을 확인하기 위해 사용했던 GLUE 벤치마크의 4개의 데이터셋을 이용합니다. 각각 CoLA(The Corpus of Linguastic Acceptability), MRPC(Microsoft Research Paraphrase Corpus), RTE(Recognizing Textua Entailment)와 QNLI(Question NLI) 입니다. 그러면 각 데이터셋에 대해 알아봅시다.
CoLA : The Corpus of Linguistic Acceptability의 약자로 분류(Classification) 태스크입니다. 해당 태스크는 문장이 문법적으로 옳은가 옳지 않은가에 대한 분류하는 것입니다. CoLA를 Fine-tuning하는 것은 다른 연구에서 아주 안정적인 성능을 보인다고 합니다. CoLA의 성능은 MCC(Matthew’s correlation coefficient)로 계산됩니다.
MRPC : Microsoft Research Paraphrase Corpus는 한 문장 쌍에 대한 분류 태스크입니다. 2개의 문장이 주어지면, 모델은 서로 다른 두 문장이 의미적으로 같은지 아닌지 구별하는 태스크입니다. MRPC는 F1 score를 통해 계산됩니다.
RTE : The Recognizing Textual Entailment는 Textual Entailment Challenge 데이터에서 수집한 문장 쌍입니다. RTE는 GLUE 벤치마크에서 두번째로 작은 데이터 셋을 가지고 있으며, RTE를 Fine-tuning하는 것이 다른 데이터셋 보다 두드러지게 불안정하다고 합니다. RTE는 Accuracy를 통해 계산됩니다.
QNLI : The question-answering Natural Language Inference는 SQuAD에서 수집한 문장 쌍으로 이루어져 있습니다. QNLi는 SQuAD에서 질문과 그에 해당하는 Paragraph의 문장에 대한 쌍으로 구성되어 있습니다. 주어진 문장이 질문에 대한 답을 가지고 있는지 구별하는 태스크입니다. QNLI는 Accuracy를 통해 계산됩니다.
- Fine-tuning(미세 조정)
Fine-tuning에 대해 별 다른 설명이 없다면 그 모델은 기존 BERT 논문에서 제안한 Fine-tuning 방법을 쓴 것입니다. 기존 BERT 논문에서 실험한 Fine-tuning 방법은 입력으로 대문자를 사용하지 않는 BERT Large를 16개의 배치와 learning rate 2e-5로 두었습니다. Learning rate는 처음에 전체 학습 스탭의 10%의 반복동안 0부터 2e-5까지 선형적으로 증가합니다.(이 기법을 warm up이라고 합니다) 그리고 이후부터는 0까지 선형적으로 줄어듭니다. Dropout은 p=0.1로 적용하였고, weight decay를 0.01로 두었습니다. 모든 데이터셋에 대해 3번의 epoch만큼 훈련하였고, global gradient clipping 기법을 사용하였습니다. 기존 BERT 논문과 같이, bias correction을 사용하지 않은 AdamW optimizer를 이용하였다고 합니다.
해당 논문에서는 BERT base에 대한 실험 결과는 공개하지 않는데요, 왜냐하면 BERT base는 크기가 작아 불안정성이 없다고 알려졌기 때문입니다. 대신에, 위와 같은 Fine-tuning 방법론을 쓴 RoBERTa Large와 ALBERT Large에 대해서도 실험을 하였다고 합니다. BERT와 비교하여, RoBERTa와 ALBERT는 조금씩 다른 hyperparameter를 통해 학습하였고, 그중에 RoBERTa는 weight deacy를 0.1로 두고 gradient clipping을 수행하지 않았습니다. 그리고 ALBERT는 dropout을 사용하지 않습니다. 모델에 대한 구현은 HuggingFace의 transformer 라이브러리를 사용하였습니다.

Fine-tuning Stability : Fine-tuning 안정성을 측정하기 위해 같은 모델에 대해 Fine-tuning을 여러번 수행하여 나온 성능의 표준 편차를 계산하였습니다. 이는 각 태스크 별로 기존에 제안된 평가 지표(Accuracy, MCC, F1 Score)를 이용하였다고 합니다.
Failed runs : 모든 훈련이 끝난 최종 정확도가 각 데이터셋의 대다수의 분류기의 성능과 같거나 작을 경우(위의 Table 2의 Majority baseline 참고) 해당 Fine-tuning은 실패했다고 보았습니다.
Fine-tuning 불안정성에 대해 제안된 가설들에 대한 조사
위에 언급했듯이 이전 연구에서는 두개의 가설이 Fine-tuning 불안정성과 관련이 있다고 설명했습니다. 바로 Catastrophic forgetting과 Small training data size인데요, 이 가설이 많이 알려져있음에도 불구하고, 저자는 두 가설 모두 Fine-tuning 불안정성의 원인이 되지 않는다고 보았습니다.
가설 1. Catastrophic forgetting이 Fine-tuning 불안정성을 유발한다?
이 가설이 맞는지 이야기 하기 전에 우선 Catastrophic forgetting을 알아야 겠죠? Catastrophic forgetting은 하나의 신경망 네트워크가 두가지 서로 다른 태스크에 대해 순차적으로 훈련될 때 발생합니다. 이 현상이 발생하면 첫번째 태스크를 수행하는 능력을 두번째 태스크에 대해 훈련될때 잃어버리게 됩니다. 다시 말하면, 단일 모델이 두가지 데이터셋을 해결하기 위해 학습을 하는데, 한 데이터셋을 먼저 학습한 뒤 다른 데이터셋을 이후에 학습을 하면, 먼저 학습한 데이터를 해결하는 능력을 잃어버리게 된다는 뜻입니다. 자 그럼 이를 BERT 모델에 적용을 해봅시다. 먼저 사전 학습된 BERT 모델에 대해 Fine-tuning을 수행하면, 그 모델은 더이상 사전 학습 단계에서 수행한 Masked Language Modeling(MLM) 태스크를 더 이상 수행할 수 없게 됩니다. Catastrophic Forgetting 현상이 BERT 모델에 일어났는지 확인하기 위해 기존에 사용한 사전 학습 훈련 데이터에 대한 Perplexity를 구하여 측정할 수 있습니다. 사전 학습된 모델의 Language modeling 성능과 Fine-tuning 정확도는 서로 밀접한 연관이 있지만, Fine-tuning을 수행하고 난뒤 기존의 Masked Language Modeling 성능을 유지하는 것이 중요한지에 대해서는 아직 알려진바가 없습니다.
그러면 BERT를 Fine-tuning하는 단계에서 Catastrophic forgetting이 정확히 어떻게 일어나는지, 그리고 Fine-tuning 불안정성과 얼마나 관계 있는지에 대해 이해하는 것이 중요합니다. 이를 더 잘 이해하기 위해, 논문의 저자들은 다음과 같은 실험을 진행하였습니다. BERT를 RTE에 대해 Fine-tuning을 위에서 설정한 훈련 세팅을 사용하여 수행합니다. 이후 3개의 성공적인 Fine-tuning 모델과 3개의 실패한 Fine-tuning 모델을 골라 그 모델들의 Masked Language Modeling Perplexity를 WikiText-2 언어 모델 벤치마크 테스트 셋을 사용해 평가합니다. Catastrophic Forgetting이 모델 전반에 영향을 미쳤는지 확인하기 위해 Fine-tuning 한 모델의 레이어를 사전 학습한 모델의 레이어로 위에서부터 24 레이어까지 순차적으로 교체하였습니다. (교체를 수행하면 위에서부터 k번째 레이어는 사전학습된 모델의 레이어이고, 이후의 레이어는 Fine-tuning한 모델의 레이어가 된다.) 이에 대한 결과는 다음 그림 (a)와 (b)에서 확인할 수 있습니다.
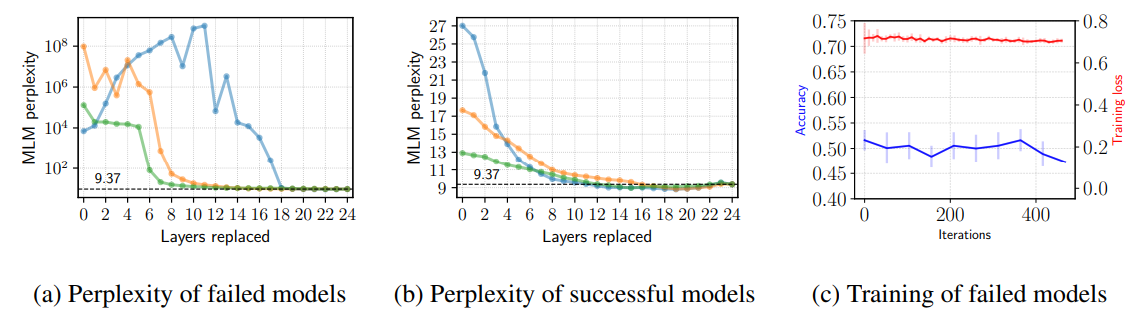
결과에 따르면 WikiText-2에 대한 perplexity가 k = 0으로 두었을때, 즉 Fine-tuning 모델 그대로 평가하였을 때 가장 성능이 떨어지고, 10개의 레이어를 기존 사전 학습된 모델과 교체하였을때 조금씩 회복하는 것으로 보아 Catastrophic Forgetting은 실패한 모델에 대해 더 잘 일어나지만, 기존에 알려진 현상과는 조금 달랐습니다. 즉, Catastrophic forgetting은 전체 모델에 대해 일어나는 것이 아니라 모델의 상위 레이어에만 영향을 준다는 뜻입니다. 결과적으로 모든 24개의 레이어중 상위 10개정도에만 영향을 미쳤고, 이는 비록 성공한 모델의 Perplexity의 증가량은 실패한 모델만큼 크지는 않지만 Catastrophic forgetting은 두 모델 모두 동일하게 일어났음을 알 수 있습니다.
헤당 가설의 또 다른 중요한 전제 조건은 Catastrophic forgetting은 모델이 새로운 태스크를 수행하는 방법을 성공적으로 학습하였을때 일어난다는 것입니다. 그러나, 해당 전제 조건은 새로운 태스크를 학습하는데 실패한 Fine-tuning 모델에 대해서도 일어났기 때문에 성립하지 않습니다. 실패한 모델에 경우 RTE 태스크의 Validation 셋의 정확도가 훈련 내내 대부분 동일하였고, Fine-tuning 태스크에 대한 훈련 로스 값도 비슷하였습니다. 이를 통해 Fine-tuning의 최적화(Optimization) 문제가 사전학습된 모델의 상위 레이어에 대해 Catastrophic Forgetting을 “일으키는” 것이라고 볼 수 있습니다. 최적화 문제로 설명하면 문제가 되는 Fine-tuning 정확도의 큰 분산(불안정성)에 대해 충분하게 설명해준다는 것을 이후 본문에서 다룰 것입니다.
가설 2. 작은 훈련 데이터셋(Small training dataset)이 Fine-tuning 불안정성을 유발한다?
작은 훈련 데이터셋은 Fine-tuning 불안정성을 설명하는 가장 많이 알려진 가설입니다. 대다수의 연구가 BERT의 Fine-tuning이 불안정한 것이 작은 수의 훈련 데이터셋과 연관이 있다고 말하고 있습니다.
작은 훈련 데이터셋이 fine-tuning 불안정성을 야기하는가 알아보기 위해 저자는 다음과 같은 실험을 수행하였습니다. 무작위로 1000개의 훈련 샘플을 CoLA, MRPC, QNLI 훈련 데이터 셋에서 각각 추출하고 BERT를 25개의 서로 다른 랜덤 시드를 이용해 각 데이터셋을 Fine-tuning하였습니다. 저자는 여기서 설정 두가지를 다르개 두어 결과를 비교하였습니다. 첫번째로, 세팅 1) 제한된 1000개의 훈련 데이터셋에 대해 3 에포크 만큼 훈련을 진행합니다. (그러면 배치가 1일 때 1000개의 제한된 데이터셋으로 총 3000 Step만큼 훈련이 되겠죠?) 두번째로는, 세팅 2) 훈련 데이터셋 전부를 에포크 3으로 훈련했을 때의 반복 횟수(Steps)만큼 제한된 1000개의 데이터셋에 대한 훈련을 진행합니다. (RTE가 총 2491개의 훈련 데이터셋이 있으니, 배치가 1일 때 2491*3 = 7473Step 만큼 1000개의 데이터셋을 이용하여 훈련이 됩니다.)
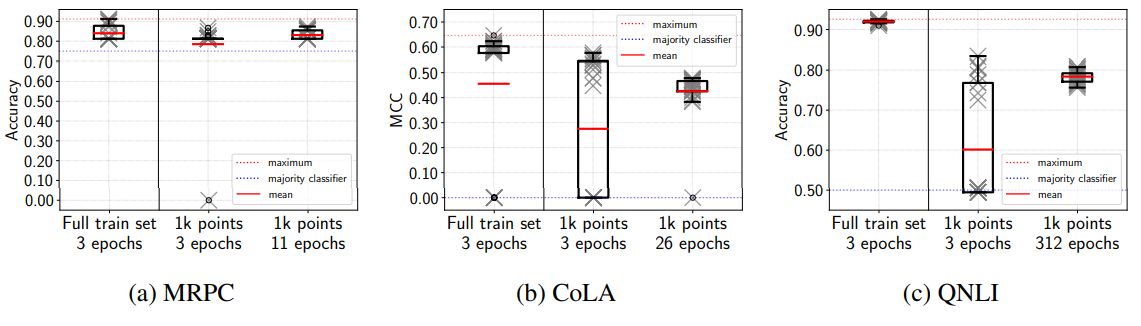
자 그러면 결과를 봅시다. 먼저 적은 데이터로 훈련하는 것이 역시나 Fine-tuning 한 모델 성능의 분산이 커지는데 영향을 미쳤고, 또한 더 많은 실패한 모델이 만들어진것을 확인할 수 있었습니다. 그러나, 2번째 설정, 즉 전체 훈련 데이터셋을 3에폭으로 훈련시킨 것과 같은 횟수로 훈련시킨 모델의 경우, 거의 완벽하게 모든 데이터셋을 사용한 Fine-tuning 모델 성능의 기존 분산으로 복구한다는 것을 발견하였습니다. 또한 세팅 2의 경우 MRPC와 QNLI에서는 실패한 모델이 만들어지지 않았고 CoLA의 경우 하나의 실패한 모델을 만들어 내었습니다. 이는 모든 훈련 세트에 훈련한 모델들의 성능 분산과 매우 유사합니다. 그러나 기존 연구와 같이 더 적은 샘플로 훈련하는 것이 모델의 일반화 성능에 영향을 미친다는 것은 여전합니다. 이는 실험에 사용한 모든 3개의 Validation 데이터셋 성능이 하락한것으로 확인할 수 있습니다.
이 실험으로 미루어보아, 훈련 데이터셋의 크기는 현재까지 Fine-tuning 안정성에 영향을 끼치지 않는다는 것을 결론지을 수 있습니다. 여기서 결과에 영향을 미치는 것은 훈련 반복 횟수라는 것을 알 수 있습니다. 해당 실험이 보여주는 것은 바로 불안정성의 증가는 더 작은 데이터셋으로 훈련하는 것보다 훈련의 반복 횟수의 감소로 이어지기 때문이라는 것 입니다. 훈련 반복 횟수은 이후에 또 다루어 이게 Fine-tuning 안정성에 많은 영향을 미친다는 것을 같이 확인해봅시다
Fine-tuning 불안정성에 대해 최적화와 일반화 관점으로 분리하여 설명하자.
실험들에 대한 결과로 알 수 있었던 것은 Catastrophic forgetting와 Small training dataset이 Fine-tuning 불안정성과 밀접한 관계가 있지만, 두 가설 모두 불안정성에 대한 근본적인 이유는 아니었다는 것입니다. 이번에는 Fine-tuning 불안정성이 Optimization(최적화) 문제이며, 이는 아주 간단한 솔루션으로 해결될 수 있다는 것을 알아 볼 것입니다. 추가적으로, 저자는 Fine-tuning 불안정성의 아주 많은 부분들이 최적화에 대한 관점으로 설명이 가능하지만, 같은 훈련 로스를 가진 Fine-tuning 모델이지만 Validation 데이터 셋의 성능이 서로 확연히 달라지는 현상은 모델의 일반화 문제에 기반을 두고 있다고 보고 있다고 합니다.
최적화의 역할
실패한 Fine-tuning 모델은 기울기 소실 문제가 일어난다
위 사진의 (b)에서 볼수 있듯이, 실패한 모델은 훈련내내 일관적인 loss가 계산된다는 것을 볼수 있습니다. 이 현상을 좀 더 잘 이해하기 위해서, 저자는 성공한 모델과 실패한 모델에 대해 BERT의 각 레이어의 l2 gradient norm을 그려보았다고 합니다. (l2는 아시죠? model의 gradient의 l2를 구하면 2x가 된답니다.) l2 gradient norm을 구하였을 때 실패한 모델의 경우 상위 레이어은 큰 gradient를 가지고 있지만, 하위 레이어로 갈수록 기울기 소실 현상이 발견되었다고 합니다. 그러면 Fine-tuning에 성공한 모델은 어떨까요? 성공한 모델의 경우 훈련 초기(70번째 iteration까지)에는 작은 gradient를 가지고 있다가, 이후 훈련이 진행될수록 gradients가 증가하는 것을 볼 수 있었다고 합니다. 또한 Fine-tuning이 끝났을 때는 성공한 모델의 gradient norm이 실패한 모델의 gradient norm보다 거의 2배 크다는 것을 발견하였습니다. 그리고 같은 현상이 RoBERTa와 ALBERT 모델에서도 발견된다는 것을 확인하였습니다. 따라서 fine-tuning에 실패한 모델의 경우 gradient가 레이어가 낮아지면 낮아질수록 gradient가 작은것을 알 수 있었고, 이는 곧 훈련이 하위 레이어까지 제대로 이루어지지 않는다는 것을 의미합니다.
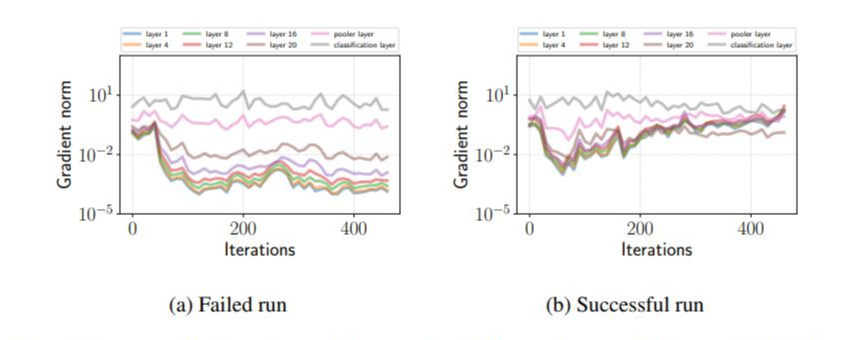
Fine-tuning단계에서 발생하는 기울기 소실 문제는 기존에 제기된 문제보다 더 해결하기 어렵습니다. 왜 그럴까요? 이는 기존 기울기 소실 문제를 해결하기 위한 방법론인 가중치 초기화에서 알아 볼 수 있습니다. 일반적으로 사용되는 Xavier initialization과 같은 가중치 초기화 방법은 네트워크의 각 레이어의 pre-activation이 평균적으로 0의 평균과 1의 분산을 갖게 하는 것을 보장해주어 기울기 소실 문제를 해결합니다. 그러나, 우리는 이미 사전 학습된 모델이 있기 때문에 가중치 초기화를 따로 적용하여 기존에 학습된 레이어의 가중치를 바꿀 수가 없습니다. 이는 미리 훈련된 가중치를 이용한다는 Fine-tuning의 아이디어와 대립되는 방법이기도 합니다.
ADAM의 bias correction의 힘
그렇다면 가중치 초기화를 사용할 수 없다면 어떻게 해결하여야 할까요? 이는 ADAM의 bias correction에 비밀이 있습니다. BERT 기반 모델을 Fine-tuning하는 이후의 연구들은 Optimizer로 ADAM을 사용하였습니다. 그러나 BERT의 저자가 처음 제시한 Fine-tuning 방법론에서는 ADAM optimizer를 사용하지만 Bias correction을 포함하지 않았습니다. 그러나 Bias correction은 기울기 소실 문제를 해결할 수 있는 중요한 요소입니다. ADAM Optimizer를 만든 Kingma and Ba는 Bias correction의 효과가 훈련 초기의 learning rate를 줄여주는 효과가 있다고 설명하였습니다. 그렇다면 이제부터 ADAM의 수식을 다시 살펴보아, 정말로 Bias correction이 초기 learning rate를 줄여주는지 확인해 봅시다.
그러면 ADAM optimizer는 무엇일까요? 바로 신경망 네트워크를 훈련시키는 알고리즘이라고 생각하시면 됩니다. 우리가 잘 알고있는 Deep learning의 신경망 네트워크는 backpropagation(역전파) 기법을 이용해 학습을 시키는데요, 역전파 기법을 간단하게 설명드리면 모델이 내놓은 예측값과 실제 정답인 레이블 값과의 오류(loss)와 각 레이어마다의 gradient(기울기)를 계산하여 값을 업데이트 시키는 겁니다. 그러나 loss를 기반으로 gradient를 바로 수정해주면 훈련이 잘 안된다는 현상이 있습니다. 따라서 학습률(learning rate)을 훈련 진행상황에 맞춰 업데이트 해주는 기법이 여러 등장하였습니다. 이는 여러 다른 사이트에서 자세히 설명하니 넘어가도록 합시다. 또한 이 논문을 이해할 정도의 수준의 여러분들이라면 당연히 역전파 기법은 알고 있으리라 생각하겠습니다.
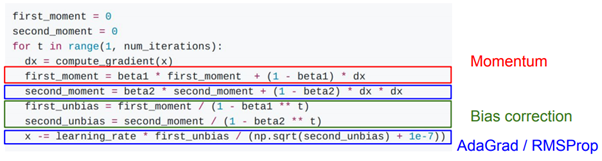
자 그러면 ADAM optimizer를 구현한 코드를 살펴봅시다. Kingma와 Ba가 제안한 ADAM optimizer는 기존에 있던 Momentum과 RMSProp이 제안한 decay rate와 AdaGrad가 제안한 지수 이동평균의 개념을 동시에 적용하고 마지막으로 Bias correction을 추가한 알고리즘입니다. 위 코드를 보시면 dx는 계산된 gradient(기울기) 값이고 이를 바로 적용하지 않고 momentum(운동량이라고 하죠?)라고 하는 값을 beta1, beta2를 이용하여 계산합니다. 여기서 beta1과 beta2는 하이퍼 파라미터로 보통 1에 가까운 0.9~0.999의 값이 할당되어 있습니다. 따라서 학습이 진행될수록 gradient가 바라보는 방향으로 운동량이 정해지게 되고, 기울기의 값이 기존의 값과 반대방향이더라도 기존의 운동량의 값이 유지 되기 때문에 학습이 매끄럽게 진행된다는 장점이 있습니다. 그러나 momentum의 주요 단점은 학습이 잘 진행될 수록 learning rate가 0에 수렴하게 되는 것입니다. 자 생각해봅시다. 처음에 학습이 잘 안된 모델의 오차는 당연히 커질 수 밖에 없고 그러면 그에 상응하는 gradient(기울기)의 값도 큽니다. 그러나 학습이 잘 진행될 수록 오차율은 줄어들고, gradient도 역시 줄어듭니다. 그러면 학습 후기의 momentum은 어떻게 될까요? 줄어드는 gradient로 인해 학습률도 역시 작아지게 되고, 학습률이 0에 수렴하게 되면 학습이 거의 진행되지 않습니다. 이 지점이 모델의 global optimum이면 좋지만, local optimum일 경우 문제가 됩니다. 그래서 나온 개념이 RMSProp으로, 최신 기울기를 제곱하여 적용하는 것으로 local optimum에 빠지지 않도록 하는 지수 이동 평균의 개념이 적용되었습니다. 이는 AdaGRAD/RMSProp에 해당되는 second momentum의 수식을 통해 확인할 수 있습니다. ADAM은 이 두가지 개념을 합친 것으로, 각각 first_momentum, second_momentum을 정의하고 있습니다. 두가지 주요 알고리즘을 적용한다는 것은 좋았지만, 여기서 문제는 학습 초기에 있습니다. 학습 초기에는 각 momentum의 값이 0이기 때문에 학습이 거의 진행되지 않습니다. 따라서 Bias correction을 도입하여 초기의 아주 작은 momentum의 값들을 보정하여 줍니다. Bias correction에 해당하는 코드를 보면, beta1, beta2에 학습 진행 횟수인 t를 제곱하여 1을 뺀값을 나누는 것을 알 수 있습니다. 따라서 t가 작은 값이면 각 momentum의 크기가 커지고, 학습이 많이 진행되 t가 커지면 커질수록 momentum의 크기가 유지된다는 것을 알 수있습니다. 따라서 현재까지도 널리 쓰이는 ADAM은 학습 초기에 모델이 잘 학습되지 않는 현상도 해결하고, 기울기의 계산에 두가지 모멘텀의 개념을 추가해 최종 목적인 global optimum에 도달할 수 있습니다. (요즘 자연어 처리에서는 Weight Decay 개념을 적용한 ADAMW를 많이쓰고 있습니다.)
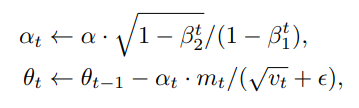
자 그러면 논문으로 돌아와 봅시다. 여기서 나타낸 수식과 위에서 설명한 값들을 비교해볼까요? mt와 vt는 각각 first momentum과 second momentum입니다. 위의 식을 보면 더 확실하겠지만, α(biased multiplication factor)가 bias correction을 통해 아주 작은값에서 1로 점점 수렴하는 것을 알 수 습니다. You et al.에서는 이러한 bias correction이 warmup의 역할과 비슷한 효과를 가진다고 합니다. warm up은 훈련시 발생하는 모델의 초기 분산현상(모델이 훈련의 갈피를 잡지못하는 현상)을 막기 위해 사용하는 아주 유명한 방법론입니다.
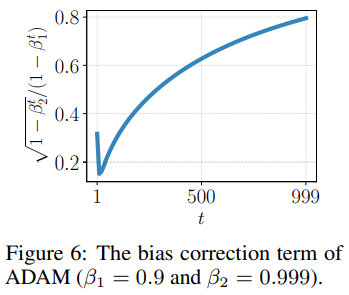
ADAM의 Bias correction이 Warm up과 같은 효과라고 하였죠? 이를 그림을 통해 확인해봅시다. 위의 그림을 보면, 훈련 초기에서 부터 학습이 진행될 수록 1에 수렴한다는 것을 알 수 있습니다. 그러면 정말로 그런지 확인해 봅시다. 저자는 Bias correction의 효과를 실험하기 위해, BERT기반 언어 모델을 RTE 데이터 셋을 이용하여 Bias correction을 도입한 ADAM optimizer로 학습한 모델과 도입하지 않은 모델을 각각 Fine-tuning해보았다고 합니다.
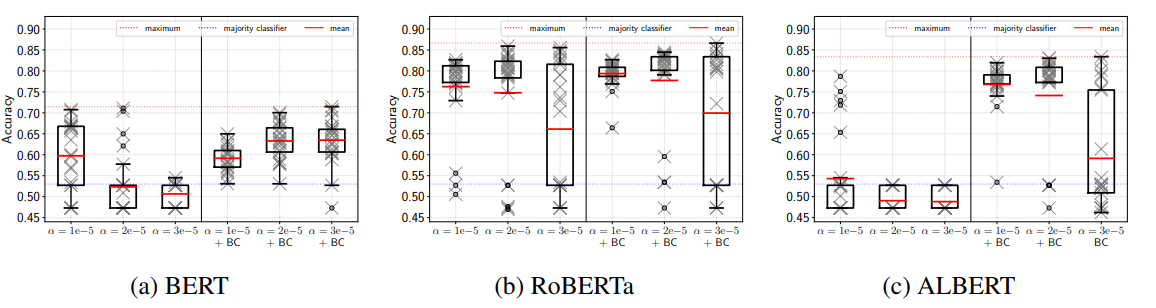
결과에 따르면 Bias correction은 3에포크 내로 훈련하는 모델들이 최고의 성능을 내기 위해 가장 유용했으며, 이는 원래 BERT 논문의 저자인 Devlin et al도 추천한 방법입니다. 다른 방법으로는 더 작은 learning rate에서 더 오래 학습하는 것으로, 더욱 안정적인 fine-tuning이 가능하다고 합니다. 위 실험을 통해 bias correction와 긴 훈련 시간이 중요하다는 사실을 알수 있었다고 합니다.
Loss surfaces
Fine-tuning이 왜 실패하는지에 대해 더 많은 사실을 알 기 위해, 저자는 성공한 모델과 실패한 모델의 loss surface 시각화를 해보았다고 합니다. θp, θf, θs로 사전학습된 모델, 실패한 모델, 성공한 모델의 파라미터를 순서대로 나타냈습니다. 2차원의 loss surface f(a,b)로 RTE, MRPC, CoLA 태스크로 파인 튜닝한 모델에 대해 시각화 해보았습니다. loss surface의 내용을 설명하면 내용이 길어지니.. loss surface 시각화에 대한 자세한 내용은(Visualizing the Loss Landscape of Neural Nets) 논문에서 확인해 보시길 바랍니다!
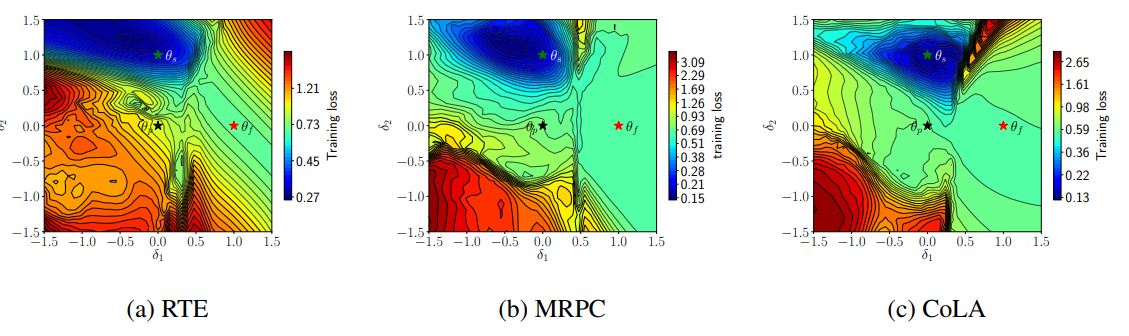
자 그림을 쉽게 설명 해 봅시다. 이 그림은 지리시간에 배운 등고선 그림으로, 별표로 표시된 θp, θf, θs는 각 모델이 학습되고 있는 위치라고 보시면 됩니다. 경사 하강법(gradient descent)에 의해 모델의 파라미터는 훈련이 진행될 수록 기울기가 높은곳에서 낮은곳으로 떨어진다는 것을 기억하고 있으시죠? 그러면 위 그림에 따르면 가장 진한 파란색 지점이 로스가 가장 낮은, 즉 global optimum이 되는 것이고 그렇지 않은 지점은 모두 sub-optimum 혹은 local optimum 이라고 보시면 됩니다. 자 그러면, 이 그림이 설명하는 주요한 포인트들을 알아보도록 합니다. 그림은 실패한 모델의 vanishing gradient(기울기 소실) 현상을 뒷받침해 줍니다. 왜냐하면 실패한 모델의 gradient(기울기)는 sub-optimal한 지점에 파라미터가 위치하여 있고, 또한 성공한 모델 파라미터가 위치하고 있는 global optimum과의 높은 벽이 존재한다는 것을 알 수 있습니다. 따라서 파라미터는 훈련이 진행되도 낮은 곳으로 진행될 수 없게 됩니다. 흥미롭게도, 모든 데이터셋에 대해 비슷한 기하학적 그림이 나왔습니다. 이 결과가 저자는 바로 Fine-tuning 불안정성이 최적화(optimization)문제라는 것을 뒷받침 한다고 주장하였습니다.
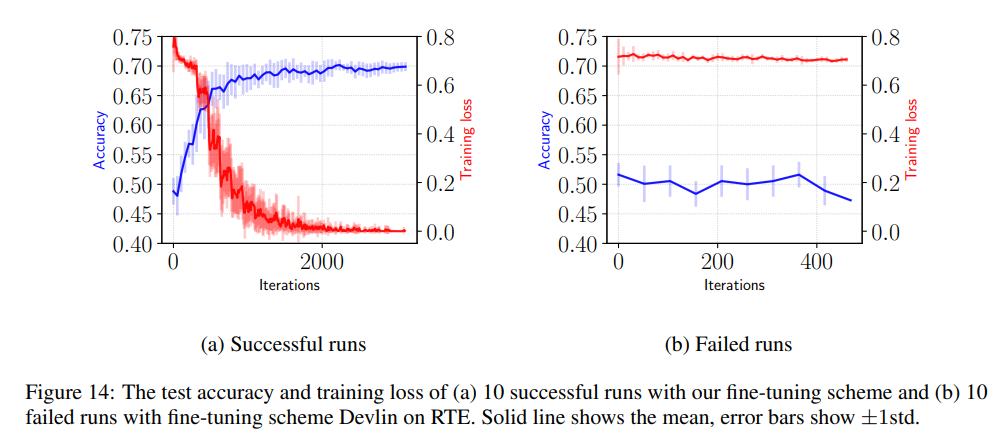
일반화의 역할
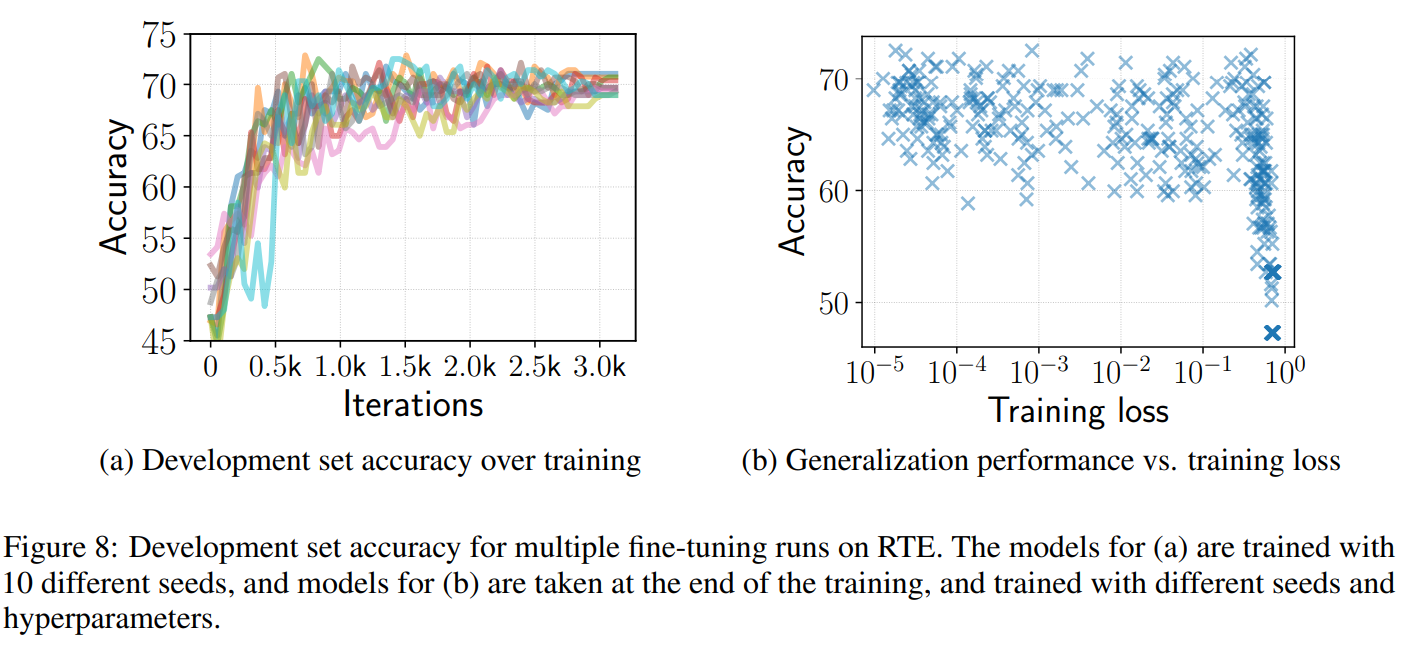
이제 Fine-tuning 불안정성을 이때까지는 최적화 문제, 즉 기울기 소실의 문제로 바라보았다면 이번에는 모델의 일반화 성능의 관점에서 바라봅시다. 동일하게 Fine-tuning된 모델이 Development 데이터셋에서 결과가 달라지는 데에 대해 일반화가 원인이 있다는 것을 보여주기 위해, 저자는 다음과 같은 실험을 진행하였다고 합니다. BERT를 RTE 데이터셋에 대해 20 에폭동안 Fine-tuning하고 Development 셋에 대해 성능을 측정하였습니다. 위 그림에서 (a)는 랜덤시드만 다르게 주었을때의 성공한 모델의 정확도의 변화이고 (b)는 Development set의 정확도와 훈련 로스 간의 2차원 그래프이며, 이는 성공한 모델이 아닌 총 450개의 모든 Fine-tuning을 거친 모델에 대해 그림을 그렸습니다.
결과적으로, 훈련 로스가 0과 가까이 근접한 모델, 즉 흔히 말하는 Overfitting이 Fine-tuning단계에서 크게 문제가 되지 않는다는 것을 알수 있습니다. 이는 이전의 연구 결과와도 일치하는 것입니다. 위의 결과에 따르면, Fine-tuning 도중에도 Development 데이터셋에 대한 성능이 많이 왔다갔다 하기 때문에 가능한 한 많이 훈련하는 것이 좋고 심지어 훈련 로스가가 10-5까지, 극단적으로 떨어져도 모델의 성능을 침해하지 않습니다.
자 그러면 이때까지의 진행한 실험과 발견들을 모아 Fine-tuning 불안정선을 2가지 관점으로 바라볼 수 있게 되었습니다. 바로 최적화(Optimization)과 일반화(Generalization)입니다. 이제부터는 밝힌 사실들을 기반으로 BERT를 어떻게 훈련시켜야 할까? 에 대해 알아봅시다.
BERT를 Fine-tuning 할 때 사용하는 간단하지만 강력한 베이스라인
위에도 언급했지만, BERT의 Fine-tuning의 불안정성은 학습 초기의 Vanishing Gradient(기울기 소실) 문제와 학습 후기의 Generalization(일반화) 문제로 볼 수 있습니다. 이를 바탕으로 흔히 사용하는 작은 데이터셋으로 트랜스포머 기반 MLM(Masked language mode)을 미세 조정하는 새로운 가이드라인을 알아봅시다. 베이스라인을 만들기 위한 기준은 다음과 같습니다.
- 1) 작은 learning rate로 Bias correction을 수행하여 학습 초기의 Vanishing gradient 현상을 방지하자.
- 2) 훈련 iteration을 늘려 training loss가 거의 0이 될 때 까지 훈련시키자.
그러면 논문에서 제시한 훈련 방법을 살펴봅시다.
1) BERT를 Bias-Correction이 있는 ADAM Optimizer으로 초기 학습율을 2e-5로 설정한다.
2) 훈련은 20 에폭동안 진행한다.
3) learning rate는 초기 10%에서는 선형적으로 증가하다가 이후에는 선형적으로 줄어들어 0이 된다.
4) 다른 하이퍼 파라이미터는 위에서 실험한 것과 동일하게 진행한다.
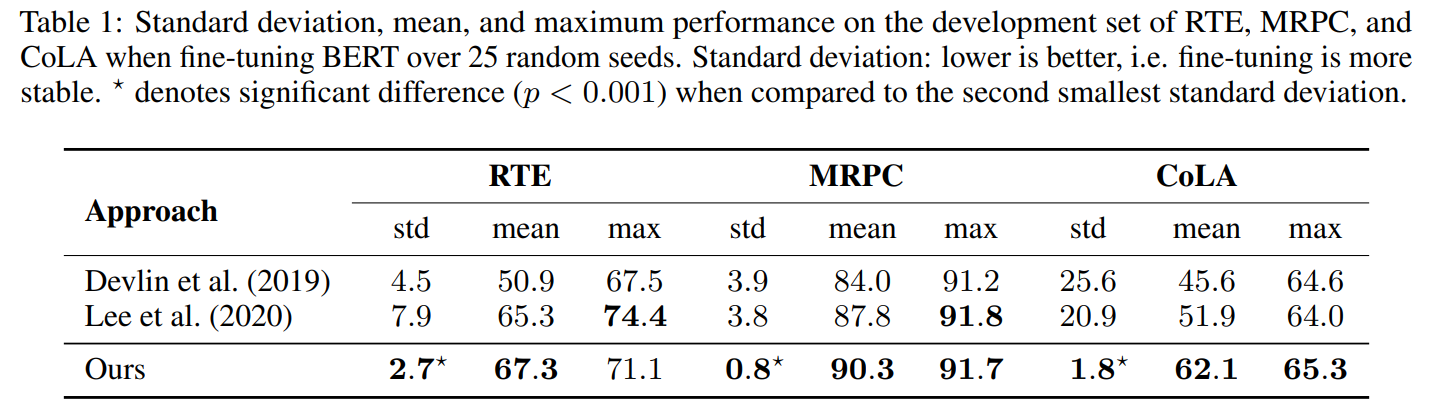
논문에서 제시한 훈련 방법을 따른 결과를 살펴봅시다. 위 표는 BERT(Devlin et al.)와 최근의 Mixout 규제(Lee et al.)를 이용한 모델과 비교를 한 것입니다. 여기서 알 수 있는 것은 먼저 논문에서 제시한 방법론이 실험한 3개의 데이터셋에서 더 안정적인 Fine-tuning 성능 보여준 다는 것을 알 수 있습니다. 이는 더 작은 표준 편차(std)값을 보면 명확할 것 같습니다. CoLA와 같은 경우는 1.8의 표준 편차 값으로 베이스라인 방법론이 기존 방법론보다 더욱 안정적인 fine-tuning을 보여준다는 것을 확인할 수 있습니다.
두번째로, 논문에서는 제시된 방법론이 전체적인 Fine-tuning 성능을 높일 수 있는지 알아보았습니다. 표 1에서 알 수 있듯이 실험한 모델 성능의 평균(mean)값이 모든 데이터셋에 대해 다 높게 나타났고, MRPC와 CoLA의 최고 성능도 높다는 것을 확인하였습니다.
마지막으로, 논문에서 제시한 작은 데이터셋에 대해 Fine-tuning 횟수를 늘리는 것이 좋은 방법이라는 것을 알 수 있습니다. 그로 인해 증가된 훈련 시간은 위 방법론에서 문제가 되지 않고, 오히려 더욱 효율적인 방법이라고 주장합니다. 왜냐하면 좋은 성능을 내기 위한 Fine-tuning 실험 횟수를 효율적으로 줄일수 있기 때문입니다.
Conclusion
이 논문에서는 Fine-tuning 불안정성으로 생각되오던 가설을 살펴보고, 새로운 훈련 방법을 알아보았습니다. 이를 몇개의 GLUE 데이터셋을 통해 실험하였습니다. Fine-tuning을 분석하여, 이때까지 정설로 여겨졌던 Catastrophic Forgetting과 Small Dataset Size는 Fine-tuning 불안정성에 대한 증거, 즉 결과이지 원인이 되지 않는다는 것을 밝혔습니다. 그 대신에, 논문에서 주장하는 불안정성에 대한 원인을 2가지로 설명하였습니다.
1. 최적화 문제(Optimization Difficulties)가 주요 문제이며, 이는 Vanishing Gradient(기울기 소실) 문제를 일으킨다.
2. 같은 로스로 훈련된 Fine-tuning 모델이 서로 다르게 일반화되어 테스트 성능이 확연하게 달라진다.
위와 같은 분석에 근거하여 저자는 간단하지만 강력한 베이스라인을 만들었고, 이는 이전 연구의 Fine-tuning 안정성적인 측면과 전체적인 성능면에서 모두 향상된 결과를 내었습니다.
자, 이번 논문 리뷰는 어떠셨나요? 유익하셨나요? 수없이 많이 나오는 BERT 시리즈에 대한 엔지니어링과 관련된 논문이었습니다. 인공지능 모델을 tensorflow, pytorch와 같은 프레임워크를 이용해 BERT와 같은 큰 모델을 훈련시키면 결과가 나오기 까지 며칠이 걸리는 경우가 많습니다. 내가 짠 코드, 혹은 공식 코드를 이용해 훈련을 진행하였는데 성능이 논문에서 제시한 만큼 안나오거나 훈련이 전혀 되지 않았다면 시간 낭비한 것만 같아 짜증나고 불안하죠. 이럴 경우 주로 모델의 구조를 바꾸거나, 하이퍼 파라미터를 바꾸거나, 혹은 코드에 오류가 있나 하는 원인을 찾으려고 하는 경우가 많은데, 비밀은 BERT 모델 그 자체, 즉 최적화 문제나 랜덤시드에 있는 경우도 있습니다. 해당 논문을 통해 여러분들의 실험에 도움이 되었길 바라며 이번 논문 리뷰를 마치겠습니다. 긴 글 읽어주셔서 감사합니다!
Reference
https://arxiv.org/abs/2006.04884
On the Stability of Fine-tuning BERT: Misconceptions, Explanations, and Strong Baselines
Fine-tuning pre-trained transformer-based language models such as BERT has become a common practice dominating leaderboards across various NLP benchmarks. Despite the strong empirical performance of fine-tuned models, fine-tuning is an unstable process: tr
arxiv.org



