안녕하세요. 이번 논문은 지난번에 소개했던 ‘Attention is all you need in speech separation’에서 사용되었던 loss에 대해서 소개하는 논문입니다. 사실 저번 논문 소개에서 loss에 대해서는 말을 하지 않기는 했었죠. 무튼 이번에는 저번에 소개했던 논문에서 사용된 loss에 대해서 알아보기 위해 본 논문을 소개해 드릴게요! 또한 본 논문은 저번에 리뷰 한 논문인 PIT논문의 후속작 입니다. PIT는 speaker tracing problem과 같은 문제가 있었는데 본 논문에서 소개하는 uPIT는 이러한 단점을 보완한 방법입니다. 그럼 이제부터 알아보겠습니다.
먼저 이 논문은 2017년 10월에 IEEE/ACM Transactions on Audio, Speech and Language Processing 라는 곳에 제출된 논문입니다. 꽤 오래된 논문이기는 하지만 최신 논문에서도 언급되는 것을 보면 요즘에도 많이 사용되는 듯합니다.
이 논문에서는 utterance-level의 PIT를 제안합니다. 일명 uPIT는 speaker에 독립적인 multi-talker speech separation을 위한 end-to-end 딥러닝 기법입니다. 특히 uPIT는 이전에 제안 된 PIT(Permutation Invariant Training)를 utterance-level의 loss function으로 확장한 방법입니다. 이러한 이유로 기존 PIT에서 문제점이었던 추론 중 추가적인 permutation problem을 해결할 필요가 없습니다(PIT에서는 입력이 frame단위여서 추론 중 speaker tracing problem이 나타났었어요). 즉 같은 speaker에 해당하지만 다른 frame에 속하는 것들을 PIT와는 다르게 동일한 출력 스트림에 정렬 시킵니다. 이렇게 uPIT loss로 학습 시킨 RNN모델은 어떠한 사전 지식(신호 길이, 화자 수, 화자의 성별 등) 없이도 multi-talker mixed speech separation을 잘 수행합니다. 추가적으로 이 논문의 저자들은 uPIT를 학습하기 위해 RNN계열인 LSTM을 사용했습니다.
그럼 이제부터는 mask에 대해서 알아봅시다. Mask는 source signal의 magnitude spectra를 추정하기 위해 사용하는 방법입니다. 그러니까 다시 말하면 source signal이 두 개 섞여 있는 mixture가 있을 때, 각각의 source를 분리하기 위해 사용하는 방법인 거죠. 여기에서는 세 가지 인기 있는 마스크를 소개하겠습니다.
첫 번째로 Ideal Ratio Mask (IRM) 입니다. 각각의 source signal에 대한 IRM은 다음과 같이 정의되어 있습니다.
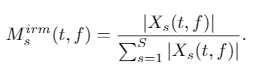
한 마디로 (source signal)/(전체 signal) 이죠.
IRM은 mixture signal인 Y의 phase가 wav 파일로 복원에 사용될 때, 모든 source가 동일한 위상을 가질 때 가장 높은 SDR을 달성합니다. 근데 보통 이런 가정은 잘못된 가정입니다. 또한 IRM의 값은 0 <= IRM(t, f) <= 1 이고, 모든 T-F 유닛에 대해서 Σ_(s=1 to S) IRM = 1 입니다(왜냐하면 모든 mask를 다 더한 다음 그 mask를 mixture에 곱하면 같은 mixture가 나와야 하기 때문이에요. 1 x a = a 인 거를 생각하면 쉽게 생각할 수 있어요!).
두 번째로 ideal Amplitude Mask (IAM) 에 대해서 알아보겠습니다. IAM은 다음과 같이 정의되어 있습니다.

IAM도 IRM과 동일하게 각 source의 phase가 mixed speech의 phase와 같을 때, 최고의 SDR 값을 얻을 수 있습니다. 당연하게도 이러한 가정은 대부분의 경우 충족되지 않습니다.
세 번째로 소개할 mask 방법은 Ideal Phase Sensitive Mask (IPSM) 입니다. IRM과 IAM은 source signal과 mixture signal의 phase 차이를 고려하지 않습니다. 이러한 점 때문에 mixture의 phase를 signal을 복원할 때 사용하면 최선의 결과가 아닌 차선의 결과가 얻어집니다. 그러나 IPSM은 phase의 차이를 고려합니다. 그리고 이러한 phase-correcting term 덕분에 Σ_(s=1 to S) IPSM = 1 이 된다고 합니다.
그런데 IPSM은 이론적으로 어떠한 구간에 닫혀 있지 않습니다. 때문에 이 논문의 저자들은 실험적으로 IPSM의 대부분이 0 <= IPSM(t, f) <= 1 이라는 것을 확인했습니다. 또한 대략 20%의 값이 음수라고 합니다. 그러나 이러한 음수 값은 보통 0에 근접한 값이기 때문에 max(0, ISPM(t, f)) 를 사용해서 음수 값이 나오면 0으로 치환했다고 합니다. 이를 Ideal Non-negative PSM (INPSM) 이라고 합니다. 아래에서 IPSM의 수식을 볼 수 있습니다.
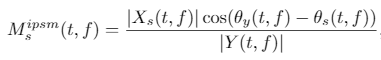
Training criterion
모델의 훈련 자체는 우리가 잘 알고 있는 MSE를 통해 진행됩니다. 아래와 같은 식을 통해 훈련이 진행되는데, 여기서 M_s는 s source에 대한 target mask이고, M̂ 은 모델로부터 추정된 값 입니다. 하지만 이 수식에는 두 가지 문제점이 있습니다. 그 중 첫 번째는 무음 세그먼트의 경우 |X_s(t, f)| = 0 이고 |Y(t, f)| = 0 이므로 target mask가 잘 정의되지 않는다는 문제점이 있습니다(왜냐하면 mask의 경우 분모에 magnitude의 값이 들어가는데 이 값이 0이 되면 제대로 된 정의가 되지 않기 때문 이예요). 두 번째 문제로는 source signal과 true signal사이의 에러를 측정하는 대신 mask 사이의 에러를 측정해야 한다는 문제가 있습니다.
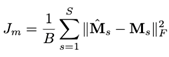
이러한 문제를 해결하기 위해서 mask 사이의 에러를 측정하는 것이 아닌 다이렉트로 magnitude와 magnitude 사이의 에러를 측정합니다. 식은 아래와 같으며, Â은 모델로부터 추정된 mask값을 mixed signal의 magnitude 값에 element wise 곱을 한 것입니다. 이렇게 하면, 무음 구간의 경우 mask 추정의 정확도에 영향을 미치지 않아 적절한 학습이 가능해집니다. 여기서 더해 앞에서 소개한 PSM을 사용하게 되면 식은 가장 아래의 식과 같이 변경되어지고, 이를 통해 target의 값이 mixed signal과 single phase signal의 차이를 측정하여 이를 다시 원본 source의 magnitude에 element wise 곱으로 곱하는 식으로 쉽게 변경됩니다(어렵게 제가 작성을 했는데요. 가장 아래 식의 뒷 부분 식을 말로 풀어 쓰니까 이렇게 되어버리네요. 그냥 식만 보고 이해하는 것이 쉽겠어요). 이렇게 되면 이 task의 상한선은 위에서 소개한 IPSM의 값이 되어버립니다.
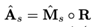

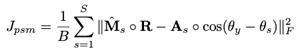
PERMUTATION INVARIANT TRAINING
> Conventional Muliti talker separation
예전의(사실 불과 몇 년 전이지만) 딥러닝 베이스 speech separation에서는 아래 그림과 같이 multi class regression 문제를 해결하는 방식으로 문제를 해결했습니다. 그렇게 추론된 mask를 mixed segment에 element wise 곱을 통해 계산해서 source를 각각 분리하는 방법으로 진행됐습니다.

> Label permutation problem
학습 시 에러가(예를 들면 위에서 소개한 J_psm 과 같은 식을 말하는 거예요) clean magnitude와 모델을 통해 추론된 값에 의해 계산되는데, 이 때 위에서 말한 예전의 방법대로 계산하게 되면 모델의 출력 중 어떤 출력이 s1인지 s2인지 알 수 없게 됩니다. 이를 label permutation problem이라고 하고, 이러한 문제 때문에 loss가 줄어들지 않는 문제가 발생합니다. 이를 해결하기 위한 방법이 permutation invariant training이며, 이 방법이 바로 아래 나옵니다.
> Permutation Invariant Training
추론 모델의 종단에서 출력된 mask가 어디에 속하는(s1인지 s2인지) 것인지 알 수 없어 loss 계산을 효율적으로 할 수 없는 permutation problem을 풀기 위해 permutation invariant training(PIT) 이라는 방법론이 나왔습니다. 기본적인 방법은 아래 그림에서 확인할 수 있습니다.

자세한 사항은 이전 포스팅 >>여기<< 에서 확인하실 수 있습니다. 여기서는 간단하게 PIT를 설명하겠습니다. PIT에서 중요한 부분은 위 그림에서 점선이 쳐진 네모 칸 안의 Pairwise scores 부분입니다. 이 부분이 하는 역할은 다음과 같습니다. 먼저 입력으로부터 예측된 cleaned speech를 받아옵니다. 이때 cleaned speech는 2개이상 이겠죠? 이렇게 받아온 값들을 정답 label들과 비교해 loss를 계산해줘야 하는데, 이때 기존과는 다른 permutation loss란 것을 사용합니다. Permutation loss란 간단히 말해 모델로부터 예측된 cleaned speech1과 label speech1을 먼저 MSE를 사용해 loss를 구하고 다음으로 cleaned speech1과 label speech2 를 MSE를 사용해 loss를 구합니다. Cleaned speech2에 대해서도 같은 작업을 합니다. 이렇게 구한 loss들 중 더 작은 loss만을 사용하여 모델을 학습시키는 방법이 PIT 방법입니다.
Utterance-level PIT
이 논문에서의 주요 내용이 바로 이 부분입니다. Utterance-level PIT를 사용함으로써 아주 간단하게 이전 포스팅 >>여기<< 에서의 문제점이었던 하나의 utterance에 대한 speaker tracing 문제를 해결했습니다.
그럼 이제 어떻게 이 문제를 해결했는지 살펴보겠습니다. 이 논문은 진짜 간단하게 하나의 utterance에 해당하는 모든 데이터를 모델의 입력으로 넣어 utterance에 대한 tracing 문제를 해결했습니다(진짜 간단하죠?). 그래서 이 논문의 제목이 utterance-level Permutation Invariant Training(uPIT) 입니다. 특히, 이 논문에서는 위에서 소개한 frame-level PIT 에서 사용된 loss function을 조금 변형해서utterance-level loss function으로 사용합니다(사실 변형한 것도 아니고 거의 완전히 똑같은 함수를 사용해요). 아래 식은 위에서 본 식이라는 것을 알겠죠? 단지 기존에는 frame단위로 적용된 식이 이제는 utterance단위로 적용된다고 생각하시면 됩니다.
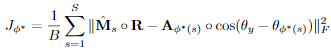

이제 이 모델은 입력으로 전체 utterance를 받고 위의 식을 loss function으로 사용하기 때문에 위의 그림에서의 pairwise scores 는 전체 utterance에 대해서 모든 출력 frame들이 같은 permutation을 따르게 됩니다. 즉 한 utterance에 대해서는 frame들이 섞이지 않는다는 말입니다. 이렇게 uPIT에 대한 소개를 했습니다. 아주 간단한 방법으로 기존의 문제점을 해결했다는 점이 흥미롭습니다.
마지막으로 uPIT에서는 slient channel이라는 세 번째 출력 뉴런을 만들어 세 명의 speaker에 대한 부분도 처리할 수 있게끔 만들었습니다. 특히 이 모델의 세 번째 출력 뉴런을 위해 두 혼합 음성보다 70db 낮은 white Gaussian noise를 사용하여 wsj0-2mix 데이터 셋을 학습하였습니다. 이렇게 wsj0-2mix와 wsj0-3mix 데이터 셋을 함께 학습하고 테스트한 결과 입력되는 음성에 화자가 몇 명이 있는지 모델에 가르쳐주지 않아도 모델이 적절히 분리해내는 것을 확인할 수 있었습니다(아래의 그림을 보시면 두 명의 speaker가 입력으로 들어올 경우에 slient channel에 정말 낮은 db이 출력된다는 것을 확인할 수 있어요). 이는 굉장히 중요한 발견으로 speaker separation을 하는데 화자의 개수라는 추가정보가 필요하지 않을 수도 있다는 발견을 한 것입니다.

이렇게 uPIT 논문을 모두 살펴보았습니다. 이제 speech separation 태스크에서 널리 사용되는 loss function이 어떠한 직관을 가지고 나타났는지 알게 되었습니다. 그럼 다음으로는 speech separation에서 큰 퀀텀점프를 이루었던 Conv-TasNet에 대해서 알아보도록 하겠습니다. 다음을 기대해주세요!!!
Reference
https://arxiv.org/abs/1703.06284
Multi-talker Speech Separation with Utterance-level Permutation Invariant Training of Deep Recurrent Neural Networks
In this paper we propose the utterance-level Permutation Invariant Training (uPIT) technique. uPIT is a practically applicable, end-to-end, deep learning based solution for speaker independent multi-talker speech separation. Specifically, uPIT extends the
arxiv.org



